NEU
Proxify is bringing transparency to tech team performance based on research conducted at Stanford. An industry first, built for engineering leaders.
Learn more













ETL-Entwickler erstellen die Pipelines, die Rohdaten in brauchbare Formate für Business Intelligence, Analysen und maschinelles Lernen umwandeln. In diesem Leitfaden erfahren Sie alles, was Sie wissen müssen, um erstklassige ETL-Talente einzustellen, die Ihrem Unternehmen helfen, Daten effektiv zu nutzen.
Über ETL-Entwicklung
Die ETL-Entwicklung ist das Herzstück der Datentechnik. Es geht darum, Daten aus verschiedenen Quellen zu extrahieren, sie so umzuwandeln, dass sie den Geschäftsanforderungen entsprechen, und sie in eine Speicherlösung wie ein Data Warehouse oder einen Data Lake zu laden.
Heutige ETL-Entwickler arbeiten mit Tools wie Apache Airflow, Talend, Informatica, Azure Data Factory und dbt (data build tool). Sie programmieren häufig in SQL, Python oder Java und nutzen zunehmend Cloud-basierte Dienste von AWS, Azure und Google Cloud.
Ein erfahrener ETL-Entwickler stellt nicht nur sicher, dass die Daten zuverlässig übertragen werden, sondern auch, dass sie sauber, optimiert und für nachgelagerte Anwendungsfälle wie Dashboards, Berichte und prädiktive Modellierung bereit sind.
ETL vs. ELT
Während ETL (Extrahieren, Transformieren, Laden) und ELT (Extrahieren, Laden, Transformieren) ähnlichen Zwecken bei der Datenintegration dienen, unterscheiden sich die Reihenfolge der Operationen und die idealen Anwendungsfälle erheblich. Bei herkömmlichen ETL-Workflows werden die Daten transformiert, bevor sie in das Zielsystem geladen werden - ideal für Umgebungen vor Ort und wenn die Transformationen komplex oder sensibel sind.
ELT hingegen kehrt diese Reihenfolge um, indem zunächst Rohdaten in ein Zielsystem geladen werden - in der Regel ein modernes Cloud-Data-Warehouse wie Snowflake, BigQuery oder Redshift - und dann an Ort und Stelle transformiert werden.
Dieser Ansatz nutzt die skalierbare Rechenleistung von Cloud-Plattformen, um große Datensätze effizienter zu verarbeiten, und vereinfacht die Pipeline-Architektur. Die Entscheidung zwischen ETL und ELT hängt oft von der Infrastruktur, dem Datenvolumen und den spezifischen Geschäftsanforderungen ab.
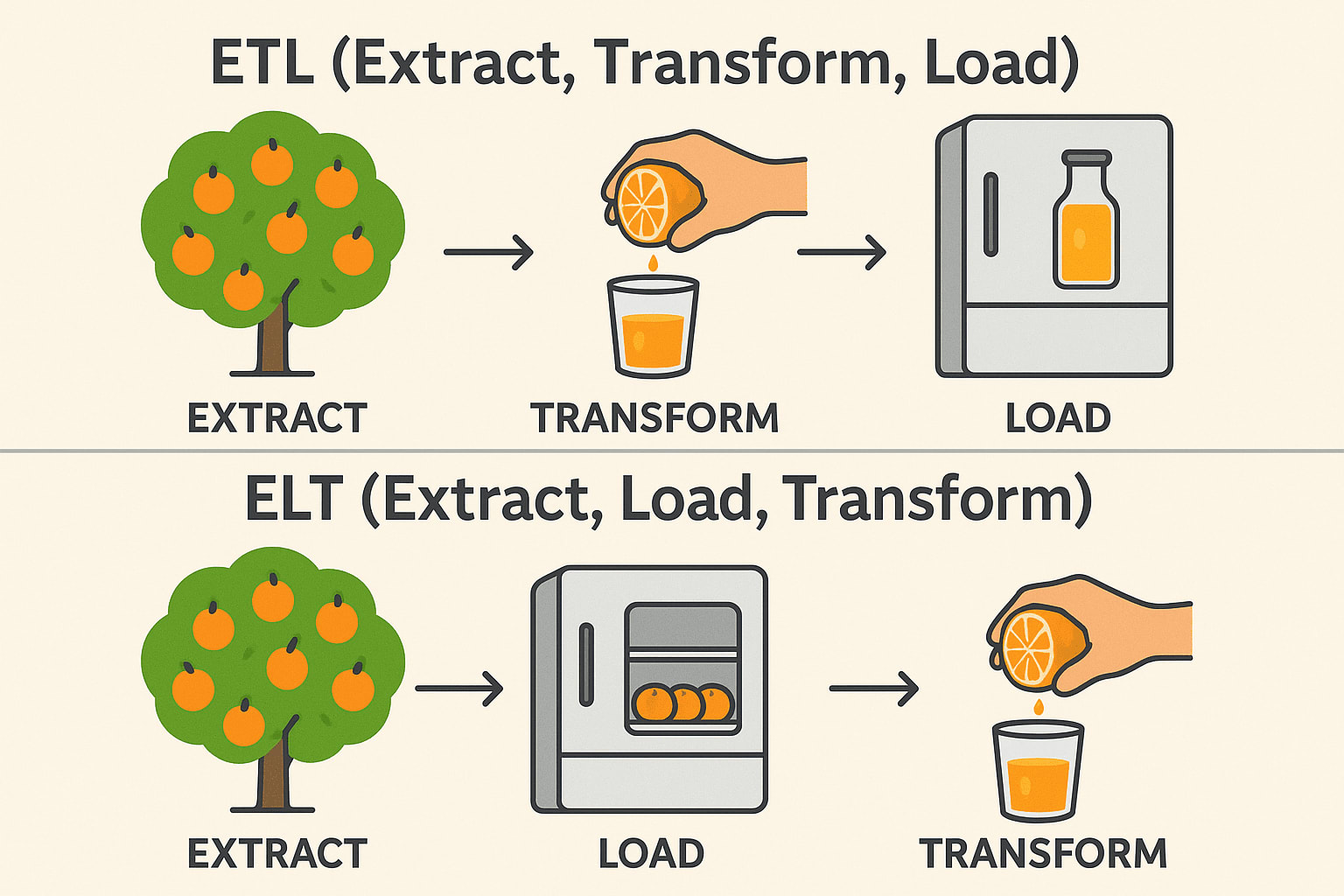
ETL (Extrahieren → Transformieren → Laden)
Extrahieren: Orangen vom Baum pflücken (Rohdaten aus Datenbanken, APIs oder Dateien sammeln). Transformieren: Sie vor dem Speichern zu Saft pressen (Daten bereinigen, filtern und formatieren). Laden: Lagern Sie den fertigen Saft im Kühlschrank (Speichern Sie strukturierte Daten in einem Data Warehouse). Gebräuchlich in: Finanzen und Gesundheitswesen (Daten müssen vor der Speicherung sauber sein).
ELT (Extrahieren → Laden → Transformieren)
Extrahieren: Orangen vom Baum pflücken (Rohdaten aus Datenbanken, APIs oder Dateien sammeln). Laden: Legen Sie die ganzen Orangen zuerst in den Kühlschrank (Speichern Sie die Rohdaten in einem Data Lake oder Cloud Warehouse). Transformieren: Bei Bedarf Saft herstellen (Daten später verarbeiten und analysieren). Gebräuchlich in: Big Data & Cloud (schnellere, skalierbare Transformationen). Technischer Stapel: Snowflake, BigQuery, Databricks, AWS Redshift.
Branchen und Anwendungen
ETL-Entwickler sind in zahlreichen Branchen unverzichtbar, darunter:
- Finanzen: Konsolidierung von Transaktionsdaten für die Berichterstattung und Betrugserkennung.
- Gesundheitswesen: Integration von Patientendaten über verschiedene Systeme hinweg zur Analyse.
- Einzelhandel & eCommerce: Zentralisierung von Kunden- und Verkaufsdaten für gezieltes Marketing und Bestandsmanagement.
- Telekommunikation: Zusammenfassen von Nutzungsdaten zur Verbesserung der Dienste.
- Technologie: Aufbau von zuverlässigen Daten-Backbones für SaaS-Plattformen und KI-Modelle.
Unabhängig von der Branche sind Unternehmen zunehmend auf genaue, zeitnahe Daten angewiesen, was qualifizierte ETL-Entwickler zu einem entscheidenden Faktor macht.
Unverzichtbare Fähigkeiten für ETL-Entwickler
Wenn Sie einen ETL-Entwickler einstellen, sollten Sie Bewerbern den Vorzug geben, die diese Kernkompetenzen aufweisen:
- Starke SQL-Kenntnisse: SQL ist nach wie vor die Lingua Franca der Datenbanken. ETL-Entwickler müssen effiziente Abfragen schreiben, um Daten genau und schnell zu extrahieren und umzuwandeln.
- Erfahrung mit ETL-Tools: Praktische Erfahrung mit ETL-Plattformen wie Informatica, Talend oder Airflow stellt sicher, dass sie robuste und skalierbare Pipelines aufbauen können, ohne das Rad neu zu erfinden.
- Datenmodellierung: ETL-Entwickler müssen verstehen, wie Daten strukturiert sind. Wenn Sie wissen, wie man Schemata wie Stern- und Schneeflockenmodelle entwirft, können Sie sicherstellen, dass die Daten für Berichte und Analysen effizient organisiert sind.
- Skriptsprachen: Sprachen wie Python oder Bash sind für die Erstellung von benutzerdefinierten Skripten, Automatisierung und Integrationen, die über das hinausgehen, was ETL-Tools standardmäßig bieten, von entscheidender Bedeutung.
- Cloud-Datendienste: Die Verlagerung in die Cloud beschleunigt sich aufgrund von Skalierbarkeit, Kosteneinsparungen und verwalteten Diensten. Kenntnisse in AWS Glue, Azure Data Factory oder Google Cloud's Dataflow bedeuten, dass der Entwickler in modernen, flexiblen Umgebungen arbeiten kann, in denen die Infrastruktur mit Ihren Geschäftsanforderungen wachsen kann.
- Problemlösung: Die ETL-Arbeit ist voller Überraschungen - unerwartete Datenanomalien, fehlgeschlagene Ladevorgänge und Leistungsengpässe. Starke Problemlösungsfähigkeiten stellen sicher, dass die Entwickler Probleme schnell diagnostizieren und beheben können, ohne den Betrieb zu stören.
- Leistungsoptimierung: Mit zunehmendem Datenvolumen steigt auch die Effizienz. Entwickler, die wissen, wie man Pipelines optimiert, helfen Kosten zu senken, Zeit zu sparen und die Zuverlässigkeit des gesamten Datenökosystems zu verbessern.
Ein erstklassiger ETL-Entwickler schreibt auch klaren, wartbaren Code und versteht die Grundsätze von Data Governance und Sicherheit.
Nice-to-have-Fähigkeiten
Die folgenden Fähigkeiten sind zwar nicht zwingend erforderlich, können aber gute ETL-Entwickler auszeichnen:
- Erfahrung mit Streaming-Daten: Echtzeit-Analytik wird immer beliebter. Die Kenntnis der Arbeit mit Tools wie Kafka oder Spark Streaming ermöglicht es Entwicklern, Lösungen zu erstellen, die sofort auf neue Daten reagieren.
- Kenntnisse von APIs: Da Unternehmen mit zahllosen Plattformen von Drittanbietern zusammenarbeiten, ist die Beherrschung von APIs ein wesentlicher Vorteil für die nahtlose Integration verschiedener Datenquellen.
- Containerisierung: Tools wie Docker und Kubernetes machen ETL-Bereitstellungen portabler und stabiler und helfen Unternehmen, Umgebungen effizienter zu verwalten.
- Data-Warehousing-Kenntnisse: Ein tiefes Verständnis von Warehouses wie Snowflake, Redshift oder BigQuery ermöglicht es Entwicklern, das Laden und Abfragen riesiger Datensätze zu optimieren.
- DevOps und CI/CD: Automatisierte Bereitstellungen und Testpipelines werden zum Standard in der Datentechnik und sorgen für schnellere und zuverlässigere Aktualisierungen von ETL-Prozessen.
- Business Intelligence-Integration: Entwickler, die ihre Pipelines mit Reporting-Tools wie Tableau, Power BI oder Looker abstimmen, schaffen einen noch größeren Mehrwert, indem sie einen nahtlosen Zugriff auf saubere, strukturierte Daten ermöglichen.
Diese zusätzlichen Funktionen können von großem Nutzen sein, wenn Ihre Datenanforderungen immer anspruchsvoller werden.
Interviewfragen und Beispielantworten
Hier sind einige Fragen, die Ihnen bei der Beurteilung der Bewerber helfen sollen:
1. Können Sie die komplexeste ETL-Pipeline beschreiben, die Sie gebaut haben?
Achten Sie auf: Größe der Datensätze, Anzahl der Transformationen, Strategien zur Fehlerbehandlung.
Beispielantwortung: Ich habe eine Pipeline erstellt, die Benutzerereignisdaten aus mehreren Anwendungen extrahiert, die Daten bereinigt und zusammengeführt, sie mit Informationen von Drittanbietern angereichert und in Redshift geladen. Ich habe die Ladeleistung durch Partitionierung der Daten optimiert und AWS Glue für die Orchestrierung verwendet.
2. Wie stellen Sie die Datenqualität während des ETL-Prozesses sicher?
Suchen Sie nach: Datenvalidierungsmethoden, Abgleichsschritte, Fehlerprotokollierung.
Beispielantwortung: Ich führe in jeder Phase Kontrollpunkte ein, verwende Tools zur Erstellung von Datenprofilen, protokolliere Anomalien automatisch und richte Warnmeldungen ein, wenn Schwellenwerte überschritten werden.
3. Wie würden Sie einen ETL-Job optimieren, der zu langsam läuft?
Suchen Sie nach: Partitionierung, Parallelverarbeitung, Abfrageoptimierung und Hardware-Tuning.
Beispielantwortung: Ich beginne mit der Analyse von Abfrageausführungsplänen, überarbeite dann Transformationen im Hinblick auf ihre Effizienz, führe inkrementelle Lasten ein und erhöhe bei Bedarf die Rechenressourcen.
4. Wie gehen Sie mit Schemaänderungen in Quelldaten um?
Suchen Sie nach: Strategien für Anpassungsfähigkeit und Robustheit.
Beispielantwortung: Ich baue eine Schemavalidierung in die Pipeline ein, verwende Versionskontrolle für Schemaaktualisierungen und entwerfe ETL-Aufträge so, dass sie sich dynamisch anpassen oder mit Warnmeldungen ordnungsgemäß abbrechen.
5. Welche Erfahrungen haben Sie mit Cloud-basierten ETL-Tools gemacht?
Suchen Sie nach: Praktische Erfahrung und nicht nur theoretisches Wissen.
Beispielantwortung: Ich habe AWS Glue und Azure Data Factory ausgiebig genutzt, um serverlose Pipelines zu entwickeln und native Integrationen mit Speicher- und Rechenservices zu nutzen.
6. Wie würden Sie einen ETL-Prozess entwerfen, der sowohl vollständige als auch inkrementelle Ladungen verarbeiten kann?
Beispielantwortung: Für vollständige Ladungen entwerfe ich den ETL, um die Zieltabellen abzuschneiden und neu zu laden, geeignet für kleine bis mittlere Datensätze. Für inkrementelles Laden implementiere ich Mechanismen zur Erfassung von Änderungsdaten (CDC), entweder über Zeitstempel, Versionsnummern oder Datenbank-Trigger. In einem PostgreSQL-Setup könnte ich zum Beispiel logische Replikations-Slots nutzen, um nur die geänderten Zeilen seit der letzten Synchronisierung zu ziehen.
7. Welche Schritte würden Sie unternehmen, um eine Datenpipeline zu beheben, die zeitweise fehlschlägt?
Beispielantwortung: Zunächst überprüfe ich die Pipeline-Protokolle, um Muster zu erkennen, wie z. B. zeitbasierte Ausfälle oder Datenanomalien. Dann isoliere ich die fehlerhafte Aufgabe - wenn es sich um einen Transformationsschritt handelt, führe ich ihn mit Beispieldaten lokal erneut aus. Ich richte häufig Wiederholungsversuche mit exponentiellem Backoff und Warnmeldungen über Tools wie PagerDuty ein, um eine rechtzeitige Reaktion auf Fehler zu gewährleisten.
8. Können Sie die Unterschiede zwischen Stapelverarbeitung und Echtzeitverarbeitung erklären und wann Sie das eine dem anderen vorziehen würden?
Beispielantwortung: Bei der Stapelverarbeitung werden Daten im Laufe der Zeit gesammelt und in großen Mengen verarbeitet. Dies ist ideal für Berichtssysteme, die keine Echtzeit-Einblicke benötigen, wie z. B. Verkaufsberichte am Ende des Tages. Echtzeitverarbeitung mit Technologien wie Apache Kafka oder AWS Kinesis ist für Anwendungsfälle wie Betrugserkennung oder Empfehlungsmaschinen, bei denen es auf Millisekunden ankommt, entscheidend.
9. Wie verwaltet man Abhängigkeiten zwischen mehreren ETL-Jobs?
Beispielantwortung: Ich verwende Orchestrierungstools wie Apache Airflow, in denen ich gerichtete azyklische Graphen (DAGs) definiere, um Auftragsabhängigkeiten auszudrücken. Ein DAG könnte zum Beispiel festlegen, dass die Aufgabe "extract" abgeschlossen sein muss, bevor "transform" beginnt. Ich verwende auch die Sensormechanismen von Airflow, um auf externe Auslöser oder die Verfügbarkeit von Upstream-Daten zu warten.
10. Wie würden Sie in einer Cloud-Umgebung sensible Daten während des ETL-Prozesses schützen?
Beispielantwortung: Ich verschlüssele Daten sowohl im Ruhezustand als auch bei der Übertragung und verwende Tools wie AWS KMS für Verschlüsselungsschlüssel. Ich setze strenge IAM-Richtlinien durch, die sicherstellen, dass nur autorisierte ETL-Jobs und -Dienste auf sensible Daten zugreifen können. In Pipelines maskiere oder tokenisiere ich sensible Felder wie PII (Personally Identifiable Information) und führe detaillierte Audit-Protokolle, um Zugriff und Nutzung zu überwachen.
Zusammenfassung
Bei der Einstellung eines ETL-Entwicklers geht es um mehr als nur darum, jemanden zu finden, der Daten von Punkt A nach Punkt B bewegen kann. Es geht darum, einen Fachmann zu finden, der die Feinheiten von Datenqualität, Leistung und sich entwickelnden Geschäftsanforderungen versteht. Wir suchen Kandidaten mit einem soliden technischen Fundament, praktischer Erfahrung mit modernen Tools und einer proaktiven Herangehensweise an die Lösung von Problemen. Im Idealfall wird Ihr neuer ETL-Entwickler Ihre Datenflüsse nicht nur pflegen, sondern auch kontinuierlich verbessern, um sicherzustellen, dass die Daten Ihres Unternehmens stets vertrauenswürdig, skalierbar und einsatzbereit sind.
