NEW
Proxify is bringing transparency to tech team performance based on research conducted at Stanford. An industry first, built for engineering leaders.
Learn more













ETL-kehittäjät rakentavat putkia, jotka siirtävät ja muuntavat raakadataa käyttökelpoisiin muotoihin liiketoimintatiedustelua, analytiikkaa ja koneoppimista varten. Tässä oppaassa käydään läpi kaikki, mitä sinun on tiedettävä, jotta voit palkata huippuluokan ETL-osaajia, jotka auttavat organisaatiotasi hyödyntämään tietoja tehokkaasti.
Tietoa ETL-kehityksestä
ETL-kehitys on tietotekniikan ytimessä. Siihen kuuluu tietojen poimiminen eri lähteistä, niiden muuntaminen liiketoiminnan tarpeiden mukaisiksi ja niiden lataaminen tallennusratkaisuun, kuten tietovarastoon tai datajärveen.
Tämän päivän ETL-kehittäjät työskentelevät sellaisten työkalujen kanssa kuin Apache Airflow, Talend, Informatica, Azure Data Factory ja dbt (data build tool). He koodaavat usein SQL:llä, Pythonilla tai Javalla ja käyttävät yhä useammin AWS:n, Azuren ja Google Cloudin pilvipalveluja.
Kokenut ETL-kehittäjä ei ainoastaan varmista, että tietoja siirretään luotettavasti, vaan myös, että ne ovat puhtaita, optimoituja ja valmiita jatkokäyttötarkoituksiin, kuten kojelautoihin, raportointiin ja ennakoivaan mallintamiseen.
ETL vs. ELT
Vaikka ETL (Extract, Transform, Load) ja ELT (Extract, Load, Transform) palvelevat samankaltaisia tarkoituksia tietojen integroinnissa, toimintojen järjestys ja ihanteelliset käyttötapaukset eroavat toisistaan merkittävästi. Perinteisissä ETL-työnkuluissa tiedot muunnetaan ennen kuin ne ladataan kohdejärjestelmään - tämä on ihanteellista paikallisissa ympäristöissä ja silloin, kun muunnokset ovat monimutkaisia tai arkaluonteisia.
ELT taas kääntää tämän järjestyksen toisinpäin lataamalla ensin raakadataa kohdejärjestelmään - yleensä moderniin pilvipalvelun kaltaiseen tietovarastoon, kuten Snowflake, BigQuery tai Redshift- ja muuntamalla sen sitten paikan päällä.
Tämä lähestymistapa hyödyntää pilvialustojen skaalautuvaa laskentatehoa suurten tietokokonaisuuksien tehokkaampaan käsittelyyn ja yksinkertaistaa putkiarkkitehtuuria. ETL:n ja ELT:n välinen valinta riippuu usein infrastruktuurista, tietomäärästä ja erityisistä liiketoimintavaatimuksista.
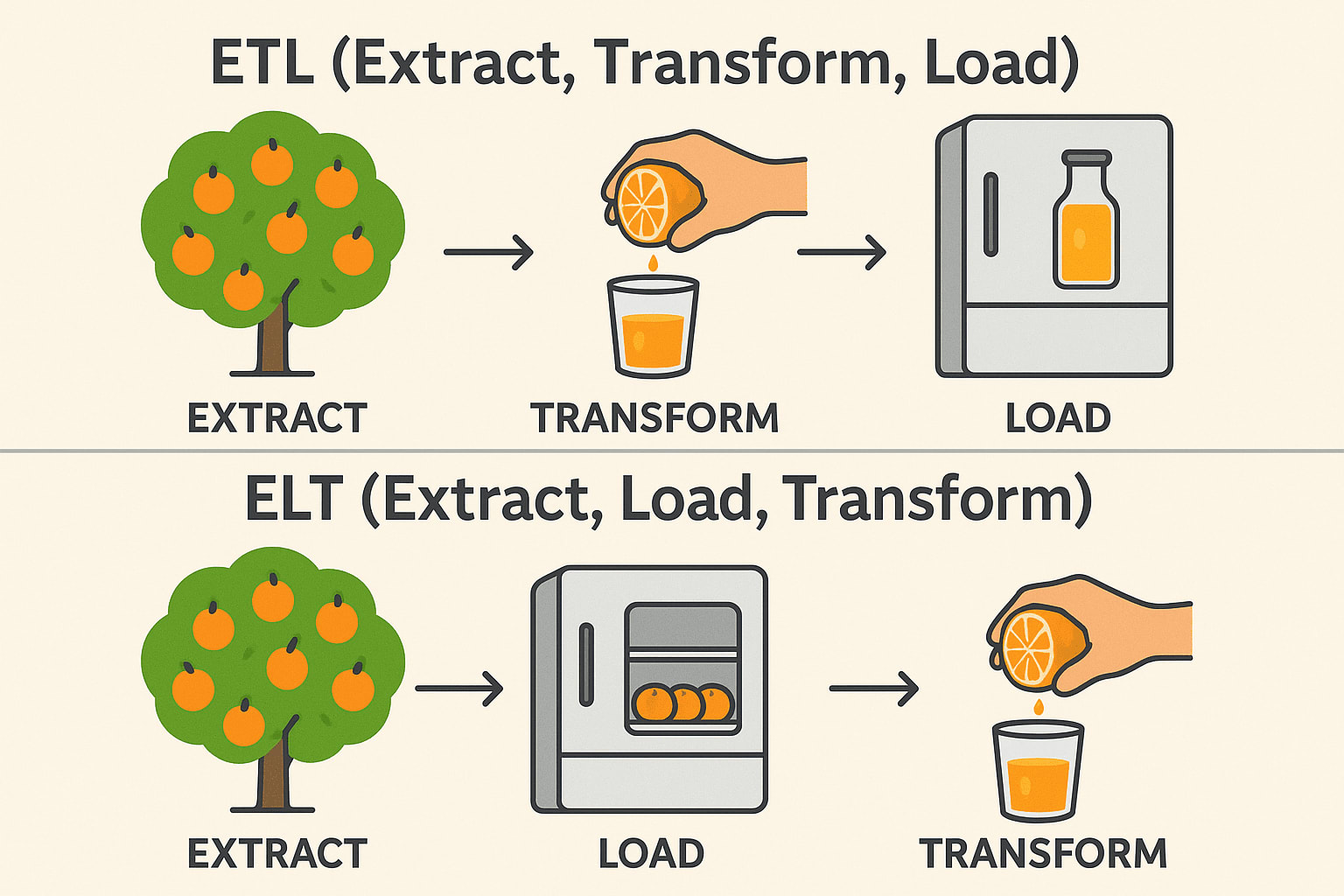
ETL (Extract → Transform → Load) ***
Extract: Poimi appelsiinit puusta (Kerää raakadataa tietokannoista, API:ista tai tiedostoista). Transform: Purista ne mehuksi ennen tallentamista (Puhdista, suodata ja muotoile tiedot). Load: Säilytä valmis mehu jääkaapissa (Tallenna strukturoitu data tietovarastoon). Käytetään yleisesti: Rahoitus- ja terveydenhuoltoalalla (tietojen on oltava puhtaita ennen tallennusta).
ELT (Extract → Load → Transform)
Extract: Poimi appelsiinit puusta (Kerää raakadataa tietokannoista, API:ista tai tiedostoista). Lataus: Säilytä kokonaiset appelsiinit ensin jääkaapissa (Tallenna raakadata data data-järveen tai pilvivarastoon). Transform: Tee mehua tarvittaessa (Käsittele ja analysoi tiedot myöhemmin). Käytetään yleisesti: Big Data & Cloud (nopeammat, skaalautuvat muunnokset). Tekninen pino: Snowflake, BigQuery, Databricks, AWS Redshift.
Toimialat ja sovellukset
ETL-kehittäjät ovat korvaamattomia useilla eri toimialoilla, kuten:
- Finance: Tapahtumatietojen konsolidointi raportointia ja petosten havaitsemista varten.
- Terveydenhuolto: Potilastietojen integrointi eri järjestelmien välillä analysointia varten.
- Jälleenmyynti ja verkkokauppa: Asiakas- ja myyntitietojen keskittäminen kohdennettua markkinointia ja varastonhallintaa varten.
- Telematiikka: Käyttötietojen yhdistäminen palvelun parantamista varten.
- Teknologia: Luotettavan datan selkärangan rakentaminen SaaS-alustoille ja tekoälymalleille.
Toimialasta riippumatta yritykset luottavat yhä enemmän tarkkoihin ja ajantasaisiin tietoihin, mikä tekee ammattitaitoisista ETL-kehittäjistä kriittisen voimavaran.
ETL-kehittäjien pakolliset taidot
Kun palkkaat ETL-kehittäjää, aseta etusijalle ehdokkaat, jotka osoittavat nämä keskeiset taidot:
- Varma SQL-osaaminen: SQL on edelleen tietokantojen kieli. ETL-kehittäjien on kirjoitettava tehokkaita kyselyjä, joiden avulla tiedot voidaan poimia ja muuntaa tarkasti ja nopeasti.
- Kokemus ETL-työkaluista: Käytännön kokemus ETL-alustoista, kuten Informatica, Talend tai Airflow, varmistaa, että he voivat rakentaa vankkoja ja skaalautuvia putkia keksimättä pyörää uudelleen.
- Datamallinnus: ETL-kehittäjien on ymmärrettävä, miten data on jäsennelty. Osaamalla suunnitella skeemoja, kuten tähti- ja lumihiutalemalleja, varmistetaan, että tiedot järjestetään tehokkaasti raportointia ja analytiikkaa varten.
- Skriptauskielet: Kielet kuten Python tai Bash ovat ratkaisevan tärkeitä, kun rakennetaan mukautettuja skriptejä, automaatiota ja integraatioita, jotka ylittävät ETL-työkalujen valmiit tarjoukset.
- Pilvitietopalvelut: Siirtyminen pilvipalveluihin kiihtyy skaalautuvuuden, kustannussäästöjen ja hallinnoitujen palvelujen vuoksi. AWS Gluen, Azure Data Factoryn tai Google Cloudin Dataflow'n osaaminen tarkoittaa, että kehittäjä voi työskennellä nykyaikaisissa, joustavissa ympäristöissä, joissa infrastruktuuri voi kasvaa liiketoimintatarpeiden mukana.
- Ongelmanratkaisu: ETL-työ on täynnä yllätyksiä - odottamattomia datapoikkeamia, epäonnistuneita latauksia ja suorituskyvyn pullonkauloja. Vahvat ongelmanratkaisutaidot varmistavat, että kehittäjät pystyvät diagnosoimaan ja korjaamaan ongelmat nopeasti ilman, että toiminta häiriintyy.
- Tehonviritys: Kun tietomäärät kasvavat, tehokkuudella on merkitystä. Kehittäjät, jotka osaavat optimoida putkistoja, auttavat vähentämään kustannuksia, säästämään aikaa ja parantamaan koko dataekosysteemin luotettavuutta.
Huippuluokan ETL-kehittäjä kirjoittaa myös selkeää, ylläpidettävää koodia ja ymmärtää tiedonhallinnan ja tietoturvan periaatteet.
Nice-to-have-taidot
Vaikka seuraavat taidot eivät ole pakollisia, ne voivat erottaa ETL-kehittäjät toisistaan:
- Kokemusta suoratoistodatasta: Reaaliaikainen analytiikka on tulossa yhä suositummaksi. Osaamalla työskennellä työkalujen, kuten Kafkan tai Spark Streamingin kanssa kehittäjät voivat rakentaa ratkaisuja, jotka reagoivat välittömästi uuteen dataan.
- Asiointirajapintojen tuntemus: Koska yritykset integroituvat lukemattomien kolmansien osapuolten alustojen kanssa, API-taidosta tulee merkittävä etu erilaisten tietolähteiden saumattomassa integroinnissa.
- Containerointi: Työkalut, kuten Docker ja Kubernetes, tekevät ETL:n käyttöönotosta siirrettävämpää ja kestävämpää, mikä auttaa organisaatioita hallinnoimaan ympäristöjä tehokkaammin.
- Tietovarastoinnin asiantuntemus: Syvä ymmärrys Snowflaken, Redshiftin tai BigQueryn kaltaisista tietovarastoista antaa kehittäjille mahdollisuuden optimoida massiivisten tietokokonaisuuksien lataamista ja kyselyjä.
- DevOps ja CI/CD: Automaattiset käyttöönotot ja testausputket ovat tulossa standardiksi tietotekniikassa, mikä takaa nopeammat ja luotettavammat päivitykset ETL-prosesseihin.
- Business Intelligence -integraatio: Kehittäjät, jotka yhdistävät putkistonsa raportointityökaluihin, kuten Tableau, Power BI tai Looker, tuovat vielä enemmän lisäarvoa mahdollistamalla saumattoman pääsyn puhtaisiin, jäsenneltyihin tietoihin.
Nämä lisäominaisuudet voivat tarjota merkittävää lisäarvoa, kun tietotarpeesi kasvavat yhä monimutkaisemmiksi.
Haastattelukysymykset ja esimerkkivastaukset
Seuraavassa on muutamia harkittuja kysymyksiä, joiden avulla voit arvioida ehdokkaita:
1. Voisitko kuvailla rakentamasi monimutkaisimman ETL-putken?.
Katso: Tietoaineistojen koko, muunnosten määrä, virheenkäsittelystrategiat.
Esimerkki vastauksesta: Rakensin putken, joka poimi käyttäjätapahtumatiedot useista sovelluksista, puhdisti ja yhdisti tiedot, rikastutti ne kolmansien osapuolten tiedoilla ja latasi ne Redshiftiin. Optimoin kuorman suorituskyvyn osioimalla datan ja käytin AWS Gluea orkestrointiin.
2. Miten varmistat tiedon laadun koko ETL-prosessin ajan?
Katso: Tietojen validointimenetelmät, täsmäytysvaiheet, virheiden kirjaaminen.
Esimerkki vastauksesta: Otan käyttöön tarkistuspisteitä jokaisessa vaiheessa, käytän tietojen profilointityökaluja, kirjaan poikkeamat automaattisesti ja asetan hälytyksiä kynnysarvojen ylittämisestä.
3. Miten optimoisit ETL-työn, joka toimii liian hitaasti?
Hae: Partitiointi, rinnakkaiskäsittely, kyselyjen optimointi ja laitteiston virittäminen.
Esimerkki vastauksesta: Aloitan analysoimalla kyselyjen suoritussuunnitelmia, sitten muokkaan muunnoksia tehokkuuden parantamiseksi, otan käyttöön inkrementaalisia kuormia ja tarvittaessa laajennan laskentaresursseja.
4. Miten käsittelette lähdetietojen skeemamuutoksia?
Hakuohjeet: Mukautuvuutta ja kestävyyttä koskevat strategiat.
Esimerkki vastauksesta: Rakennan skeeman validoinnin putkeen, käytän versionhallintaa skeeman päivityksiin ja suunnittelen ETL-työt niin, että ne mukautuvat dynaamisesti tai epäonnistuvat hienovaraisesti hälytysten avulla.
5. Mitä kokemuksia sinulla on pilvipohjaisista ETL-työkaluista?
Hakuehtona: Käytännön kokemusta eikä vain teoreettista tietoa.
Esimerkki vastauksesta: Olen käyttänyt AWS Gluea ja Azure Data Factorya laajalti, suunnitellut palvelimettomia putkilinjoja ja hyödyntänyt natiiviintegraatioita tallennus- ja laskentapalveluiden kanssa.
6. Miten suunnittelisit ETL-prosessin käsittelemään sekä täysiä että inkrementaalisia kuormia?
Esimerkki vastaus: Täydellisiä kuormia varten suunnittelen ETL:n typistämään ja lataamaan kohdetaulukot uudelleen, mikä sopii pienille tai keskisuurille tietokokonaisuuksille. Inkrementaalisia latauksia varten otan käyttöön CDC-mekanismeja (Change Data Capture) joko aikaleimojen, versionumeroiden tai tietokantatriggereiden avulla. Esimerkiksi PostgreSQL-asetuksessa saatan hyödyntää loogisia replikaatioaikoja vetääkseni vain edellisen synkronoinnin jälkeen muuttuneet rivit.
7. Mitä toimia toteuttaisit vianmäärityksessä dataputkessa, joka epäonnistuu ajoittain?
Esimerkki vastauksesta: Tarkastelen ensin putkilokit havaitakseni kuvioita, kuten aikaperusteisia vikoja tai datan poikkeavuuksia. Sitten eristän epäonnistuneen tehtävän - jos kyseessä on muunnosvaihe, suoritan sen uudelleen esimerkkitiedoilla paikallisesti. Asetan usein uusintayrityksiä eksponentiaalisella backoffilla ja hälytyksiä PagerDuty-työkalujen kaltaisten työkalujen avulla varmistaakseni oikea-aikaisen reagoinnin epäonnistumisiin.
8. Voisitko selittää eräkäsittelyn ja reaaliaikaisen käsittelyn erot ja sen, milloin valitsisit toisen toisen sijaan?.
Vastausesimerkki: Eräkäsittelyssä kerätään tietoja ajan mittaan ja käsitellään ne irtotavarana, mikä sopii erinomaisesti raportointijärjestelmiin, joissa ei tarvita reaaliaikaisia näkemyksiä, kuten päivän lopun myyntiraportteihin. Reaaliaikainen käsittely, jossa käytetään Apache Kafkan tai AWS Kinesiksen kaltaisia tekniikoita, on kriittinen käyttötapauksissa, kuten petosten havaitsemisessa tai suositusmoottoreissa, joissa millisekunnit ovat tärkeitä.
9. Miten hallitaan useiden ETL-töiden välisiä riippuvuuksia?
Esimerkki vastauksesta: Käytän Apache Airflow'n kaltaisia orkestrointityökaluja, joissa määrittelen DAG-käyriä (Directed Acyclic Graphs) ilmaisemaan työn riippuvuuksia. Esimerkiksi DAG voi määrittää, että "extract"-tehtävän on oltava valmis ennen kuin "transform"-tehtävä alkaa. Käytän myös Airflow'n anturimekanismeja odottamaan ulkoisia laukaisijoita tai tietojen saatavuutta ylävirtaan.
10. Miten suojaat pilviympäristössä arkaluonteiset tiedot ETL-prosessin aikana?
Esimerkki vastauksesta: Salaan tietoja sekä levossa että siirron aikana ja käytän salausavaimiin työkaluja, kuten AWS KMS:ää. Käytän tiukkoja IAM-käytäntöjä, joilla varmistetaan, että vain valtuutetut ETL-työt ja -palvelut voivat käyttää arkaluonteisia tietoja. Piipuissa peitän tai tokenisoin arkaluonteiset kentät, kuten PII (Personally Identifiable Information), ja ylläpidän yksityiskohtaisia tarkastuslokeja, joilla seurataan pääsyä ja käyttöä.
Yhteenveto
ETL-kehittäjän palkkaamisessa on kyse muustakin kuin vain siitä, että löydetään henkilö, joka pystyy siirtämään tietoja pisteestä A pisteeseen B. Kyse on ammattilaisen löytämisestä, joka ymmärtää tietojen laadun, suorituskyvyn ja kehittyvien liiketoimintatarpeiden vivahteet. Etsimme ehdokkaita, joilla on vahva tekninen perusta, käytännön kokemusta nykyaikaisista työkaluista ja ennakoiva lähestymistapa ongelmanratkaisuun. Ihannetapauksessa uusi ETL-kehittäjäsi ei ainoastaan ylläpidä tietovirtojasi vaan myös parantaa niitä jatkuvasti varmistaen, että organisaatiosi tiedot ovat aina luotettavia, skaalautuvia ja toimintavalmiita.
