NYHET
Proxify ger dig full insyn i utvecklarnas prestationer – ett branschunikt erbjudande som är varje CTO:s dröm.
Läs mer













ETL-utvecklare bygger pipelines som flyttar och omvandlar rådata till användbara format för affärsinformation, analys och maskininlärning. Den här guiden går igenom allt du behöver veta för att anställa topp ETL-talanger som hjälper din organisation att utnyttja data effektivt.
Om ETL-utveckling
ETL-utveckling är kärnan i datateknik. Det handlar om att extrahera data från olika källor, omvandla dem för att tillgodose affärsbehov och ladda dem i en lagringslösning som ett datalager eller en datasjö.
Dagens ETL-utvecklare arbetar med verktyg som Apache Airflow, Talend, Informatica, Azure Data Factory och dbt (data build tool). De kodar ofta i SQL, Python eller Java och använder i allt högre grad molnbaserade tjänster från AWS, Azure och Google Cloud.
En erfaren ETL-utvecklare säkerställer inte bara att data flyttas på ett tillförlitligt sätt utan också att den är ren, optimerad och redo för nedströmsanvändningsfall som instrumentpaneler, rapportering och prediktiv modellering.
ETL vs. ELT
Även om ETL (Extract, Transform, Load) och ELT (Extract, Load, Transform) tjänar liknande syften vid dataintegration, skiljer sig arbetsordningen och de ideala användningsfallen avsevärt. I traditionella ETL-arbetsflöden transformeras data innan de laddas in i destinationssystemet - idealiskt för lokala miljöer och när transformationer är komplexa eller känsliga.
ELT, å andra sidan, vänder på denna ordning genom att först ladda rådata till ett målsystem - vanligtvis ett modernt molndatalager som Snowflake, BigQuery eller Redshift- och sedan omvandla det på plats.
Detta tillvägagångssätt utnyttjar den skalbara beräkningskraften hos molnplattformar för att hantera stora datamängder mer effektivt och förenklar pipelinearkitekturen. Valet mellan ETL och ELT handlar ofta om infrastruktur, datavolym och specifika affärskrav.
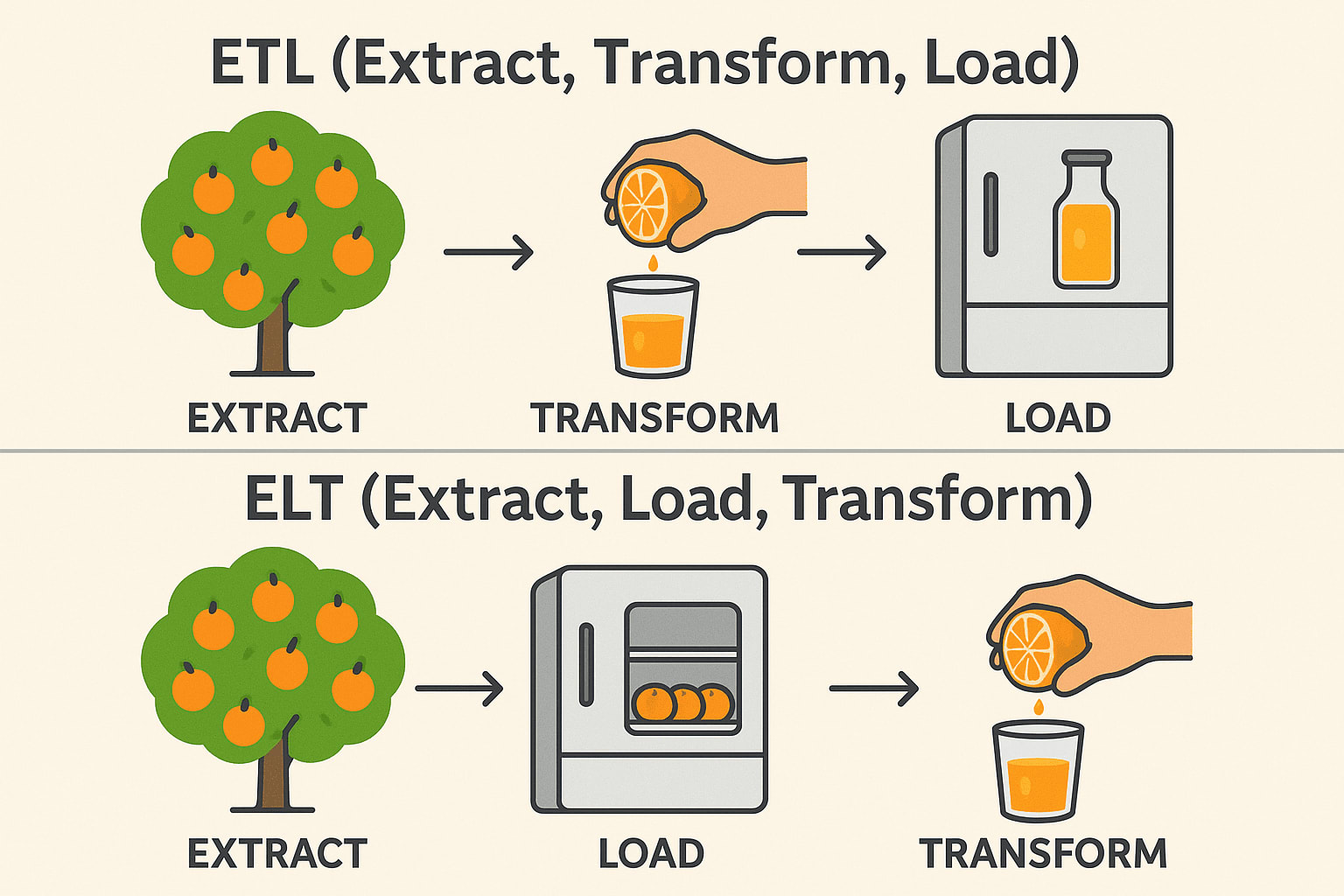
ETL (Extrahera → Transformera → Ladda)
Extrahera: Plocka apelsiner från trädet (samla in rådata från databaser, API:er eller filer). Transform: Pressa dem till juice innan de lagras (rengör, filtrera och formatera data). Load: Förvara den färdiga juicen i kylskåpet (Spara strukturerad data i ett datalager). Vanligt förekommande inom: Finans och sjukvård (data måste vara rena före lagring).
ELT (Extrahera → Ladda → Transformera)
Extrahera: Plocka apelsiner från trädet (samla in rådata från databaser, API:er eller filer). Load: Förvara de hela apelsinerna i kylskåpet först (spara rådata i en datasjö eller ett molnlager). Transform: Gör juice när det behövs (bearbeta och analysera data senare). Används ofta i: Big Data & Cloud (snabbare, skalbara transformationer). Teknisk stack: Snowflake, BigQuery, Databricks, AWS Redshift.
Branscher och tillämpningar
ETL-utvecklare är oumbärliga inom flera branscher, inklusive:
- Finans: Konsolidering av transaktionsdata för rapportering och upptäckt av bedrägerier.
- Hälsovård: Integrering av patientjournaler i olika system för analys.
- Retail & eCommerce: Centralisering av kund- och försäljningsdata för riktad marknadsföring och lagerhantering.
- Telekommunikation: Aggregering av användningsdata för att förbättra tjänsterna.
- Teknik: Bygga pålitliga data backbones för SaaS-plattformar och AI-modeller.
Oavsett bransch förlitar sig företag i allt högre grad på korrekta data i rätt tid, vilket gör skickliga ETL-utvecklare till en kritisk tillgång.
Måste-ha-färdigheter för ETL-utvecklare
När du anställer en ETL-utvecklare ska du prioritera kandidater som visar dessa kärnkompetenser:
- Stark SQL-kunskap: SQL är fortfarande databasernas lingua franca. ETL-utvecklare måste skriva effektiva frågor för att extrahera och omvandla data korrekt och snabbt.
- Erfarenhet av ETL-verktyg: Praktisk erfarenhet av ETL-plattformar som Informatica, Talend eller Airflow säkerställer att de kan bygga robusta och skalbara pipelines utan att uppfinna hjulet på nytt.
- Datamodellering: ETL-utvecklare måste förstå hur data är strukturerade. Att veta hur man utformar scheman som stjärn- och snöflingemodeller säkerställer att data organiseras effektivt för rapportering och analys.
- Skriptspråk: Språk som Python eller Bash är avgörande för att bygga anpassade skript, automatisering och integrationer utöver vad ETL-verktyg erbjuder.
- Cloud Data Services: Övergången till molnet accelererar på grund av skalbarhet, kostnadsbesparingar och hanterade tjänster. Kompetens i AWS Glue, Azure Data Factory eller Google Clouds Dataflow innebär att utvecklaren kan arbeta i moderna, flexibla miljöer där infrastrukturen kan växa med dina affärsbehov.
- Problemlösning: ETL-arbete är fullt av överraskningar - oväntade dataanomalier, misslyckade laddningar och flaskhalsar i prestanda. Starka problemlösningsförmågor säkerställer att utvecklare kan diagnostisera och åtgärda problem snabbt utan att avbryta verksamheten.
- Prestandajustering: När datavolymerna ökar är effektiviteten viktig. Utvecklare som vet hur man optimerar pipelines hjälper till att minska kostnaderna, spara tid och förbättra tillförlitligheten i hela dataekosystemet.
En ETL-utvecklare i toppklass skriver också tydlig och underhållbar kod och förstår principerna för datastyrning och säkerhet.
Bra att ha färdigheter
Även om det inte är obligatoriskt kan följande färdigheter skilja stora ETL-utvecklare från varandra:
- Erfarenhet av strömmande data: Realtidsanalys blir allt mer populärt. Att veta hur man arbetar med verktyg som Kafka eller Spark Streaming gör det möjligt för utvecklare att bygga lösningar som reagerar direkt på nya data.
- Kunskap om API:er: Eftersom företag integrerar med otaliga tredjepartsplattformar blir API-kunskaper en betydande fördel för att sömlöst integrera olika datakällor.
- Containerization: Verktyg som Docker och Kubernetes gör ETL-distributioner mer portabla och motståndskraftiga, vilket hjälper organisationer att hantera miljöer mer effektivt.
- Datalagringsexpertis: En djup förståelse för lager som Snowflake, Redshift eller BigQuery gör det möjligt för utvecklare att optimera laddning och frågor om massiva datamängder.
- DevOps och CI/CD: Automatiserade distributioner och testpipelines håller på att bli standard inom datateknik, vilket säkerställer snabbare och mer tillförlitliga uppdateringar av ETL-processer.
- Business Intelligence-integration: Utvecklare som anpassar sina pipelines med rapporteringsverktyg som Tableau, Power BI eller Looker tillför ännu mer värde genom att möjliggöra sömlös åtkomst till rena, strukturerade data.
Dessa ytterligare funktioner kan ge betydande värde när dina databehov blir mer sofistikerade.
Intervjufrågor och exempel på svar
Här är några genomtänkta frågor som hjälper dig att bedöma kandidater:
1. Kan du beskriva den mest komplexa ETL-pipeline du har byggt?
Se efter: Storlek på dataset, antal transformationer, strategier för felhantering.
Exempel på svar: Jag byggde en pipeline som extraherade användarhändelsedata från flera appar, rensade och sammanfogade data, berikade dem med information från tredje part och laddade dem i Redshift. Jag optimerade belastningsprestanda genom att partitionera data och använde AWS Glue för orkestrering.
2. Hur säkerställer du datakvalitet under hela ETL-processen?
Leta efter: Datavalideringsmetoder, avstämningssteg, felloggning.
Exempel på svar: Jag inför kontrollpunkter i varje steg, använder verktyg för dataprofilering, loggar avvikelser automatiskt och ställer in varningar för tröskelvärden som överskrids.
3. Hur skulle du optimera ett ETL-jobb som går för långsamt?
Leta efter: Partitionering, parallellbearbetning, frågeoptimering och hårdvarutuning.
Exempel på svar: Jag börjar med att analysera frågeexekveringsplaner, sedan refaktorisera transformationer för effektivitet, införa inkrementella belastningar och vid behov skala upp beräkningsresurser.
4. Hur hanterar du schemaändringar i källdata?
Leta efter: Strategier för anpassningsförmåga och robusthet.
Exempelsvar: Jag bygger in schemavalidering i pipelinen, använder versionshantering för schemauppdateringar och utformar ETL-jobb för att anpassa sig dynamiskt eller misslyckas elegant med varningar.
5. Vad är din erfarenhet av molnbaserade ETL-verktyg?
Leta efter: Praktisk erfarenhet snarare än bara teoretisk kunskap.
Exempel på svar: Jag har använt AWS Glue och Azure Data Factory i stor utsträckning, utformat serverlösa pipelines och utnyttjat inbyggda integrationer med lagrings- och beräkningstjänster.
6. Hur skulle du utforma en ETL-process för att hantera både fulla laster och inkrementella laster?
Exempelsvar: För fulla laddningar utformar jag ETL för att trunkera och ladda om måltabellerna, lämpligt för små till medelstora dataset. För inkrementella belastningar implementerar jag CDC-mekanismer (Change Data Capture), antingen via tidsstämplar, versionsnummer eller databastriggers. Till exempel, i en PostgreSQL-installation, kan jag utnyttja logiska replikeringsplatser för att bara dra de ändrade raderna sedan den senaste synkroniseringen.
7. Vilka steg skulle du ta för att felsöka en datapipeline som misslyckas periodvis?
Exempel på svar: Först granskar jag pipeline-loggarna för att upptäcka mönster, t.ex. tidsbaserade fel eller dataanomalier. Sedan isolerar jag den misslyckade uppgiften - om det är ett omvandlingssteg kör jag det igen med provdata lokalt. Jag ställer ofta in omprövningar med exponentiell backoff och varningar via verktyg som PagerDuty för att säkerställa ett snabbt svar på misslyckanden.
8. Kan du förklara skillnaderna mellan batchbehandling och realtidsbehandling, och när du skulle välja det ena framför det andra?
Exempelsvar: Batchbearbetning innebär att man samlar in data över tid och bearbetar dem i bulk, vilket är perfekt för rapporteringssystem som inte behöver insikter i realtid, som försäljningsrapporter i slutet av dagen. Realtidsbearbetning, med hjälp av tekniker som Apache Kafka eller AWS Kinesis, är avgörande för användningsfall som bedrägeridetektering eller rekommendationsmotorer där millisekunder spelar roll.
9. Hur hanterar du beroenden mellan flera ETL-jobb?
Exempel på svar: Jag använder orkestreringsverktyg som Apache Airflow, där jag definierar DAG:ar (Directed Acyclic Graphs) för att uttrycka jobbberoenden. En DAG kan till exempel ange att uppgiften "extrahera" måste slutföras innan "transformera" påbörjas. Jag använder också Airflows sensormekanismer för att vänta på externa utlösare eller uppströms datatillgänglighet.
10. Hur skulle du säkra känslig data i en molnmiljö under ETL-processen?
Exempel på svar: Jag krypterar data både i vila och i transit, och använder verktyg som AWS KMS för krypteringsnycklar. Jag verkställer strikta IAM-policyer och ser till att endast auktoriserade ETL-jobb och tjänster kan komma åt känslig data. I pipelines maskerar eller tokeniserar jag känsliga fält som PII (personligt identifierbar information) och upprätthåller detaljerade granskningsloggar för att övervaka åtkomst och användning.
Sammanfattning
Att anställa en ETL-utvecklare handlar om mer än att bara hitta någon som kan flytta data från punkt A till punkt B. Det handlar om att hitta en professionell som förstår nyanserna i datakvalitet, prestanda och utvecklande affärsbehov. Vi söker kandidater med en stark teknisk grund, praktisk erfarenhet av moderna verktyg och ett proaktivt förhållningssätt till problemlösning. Din nya ETL-utvecklare kommer inte bara att underhålla dina dataflöden utan också kontinuerligt förbättra dem, så att din organisations data alltid är pålitlig, skalbar och redo för åtgärder.
