NYHET
Proxify er åpen om utviklerens prestasjoner — det er bransjeledende, og også enhver CTOs drøm.
Finn ut mer











ETL-utviklere bygger pipelines som flytter og omdanner rådata til brukbare formater for business intelligence, analyse og maskinlæring. Denne veiledningen går gjennom alt du trenger å vite for å ansette de beste ETL-talentene som vil hjelpe organisasjonen din med å utnytte data effektivt.
Om ETL-utvikling
ETL-utvikling er kjernen i datateknikk. Det innebærer å hente ut data fra ulike kilder, transformere dem slik at de oppfyller virksomhetens behov, og laste dem inn i en lagringsløsning som et datavarehus eller en datasjø.
Dagens ETL-utviklere jobber med verktøy som Apache Airflow, Talend, Informatica, Azure Data Factory og dbt (data build tool). De koder ofte i SQL, Python eller Java, og bruker i økende grad skybaserte tjenester fra AWS, Azure og Google Cloud.
En erfaren ETL-utvikler sørger ikke bare for at dataene flyttes på en pålitelig måte, men også for at de er rene, optimaliserte og klare for nedstrøms bruk, for eksempel dashbord, rapportering og prediktiv modellering.
ETL vs. ELT
Selv om ETL (Extract, Transform, Load) og ELT (Extract, Load, Transform) tjener lignende formål innen dataintegrasjon, er rekkefølgen på operasjonene og de ideelle brukstilfellene svært forskjellige. I tradisjonelle ETL-arbeidsflyter blir dataene transformert før de lastes inn i destinasjonssystemet - ideelt for lokale miljøer og når transformasjonene er komplekse eller sensitive.
ELT, derimot, snur om på denne rekkefølgen ved først å laste inn rådata i et målsystem - vanligvis et moderne datalager i skyen som Snowflake, BigQuery eller Redshift - og deretter transformere dem på stedet.
Denne tilnærmingen utnytter den skalerbare datakraften til skyplattformer for å håndtere store datasett mer effektivt og forenkle pipeline-arkitekturen. Valget mellom ETL og ELT handler ofte om infrastruktur, datavolum og spesifikke forretningskrav.
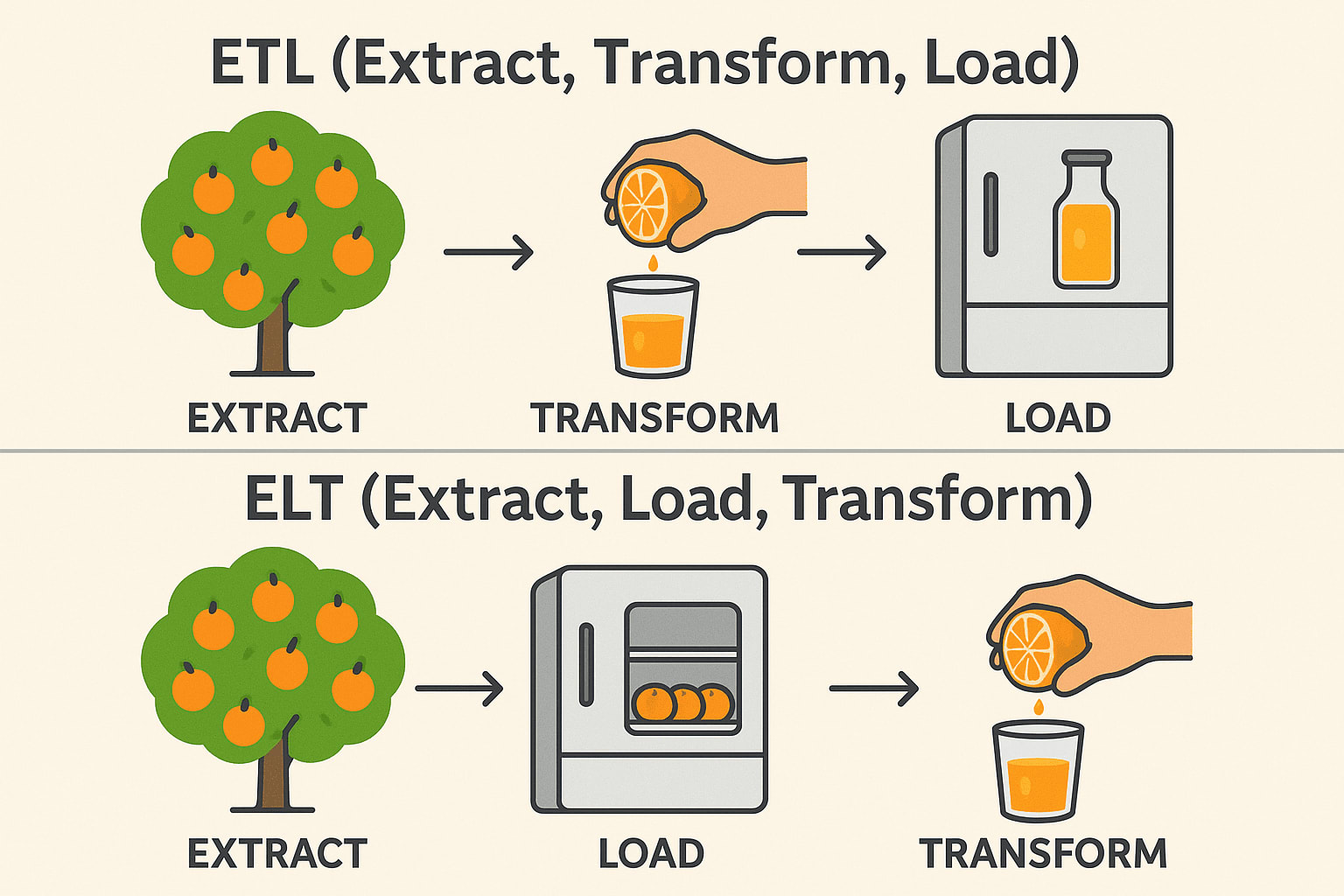
ETL (Extract → Transform → Load)
Extract: Plukk appelsiner fra treet (samle inn rådata fra databaser, API-er eller filer). Transformer: Press dem til juice før lagring (Rens, filtrer og formater dataene). Load: Oppbevar den ferdige juicen i kjøleskapet (Lagre strukturerte data i et datalager). Vanlig brukt i: Finans og helsevesen (data må være rene før lagring).
ELT (Extract → Load → Transform)
Extract: Plukk appelsiner fra treet (samle inn rådata fra databaser, API-er eller filer). Load: Lagre hele appelsiner i kjøleskapet først (Lagre rådata i en datasjø eller et skylager). Transform: Lag juice når det er nødvendig (behandle og analyser data senere). Vanlig brukt i: Big Data & Cloud (raskere, skalerbare transformasjoner). Teknisk stabel: Snowflake, BigQuery, Databricks, AWS Redshift.
Bransjer og applikasjoner
ETL-utviklere er uunnværlige i mange bransjer, blant annet:
- Finans: Konsolidering av transaksjonsdata for rapportering og oppdagelse av svindel.
- Helsevesen: Integrering av pasientjournaler på tvers av ulike systemer for analyse.
- Detaljhandel og e-handel: Sentralisering av kunde- og salgsdata for målrettet markedsføring og lagerstyring.
- Telekommunikasjon: Aggregering av bruksdata for å informere om tjenesteforbedringer.
- Teknologi: Bygge pålitelige datagrunnlag for SaaS-plattformer og AI-modeller.
Uansett bransje er virksomheter i økende grad avhengige av nøyaktige og tidsriktige data, noe som gjør dyktige ETL-utviklere til en kritisk ressurs.
Nødvendige ferdigheter for ETL-utviklere
Når du ansetter en ETL-utvikler, bør du prioritere kandidater som kan vise til disse kjerneferdighetene:
- Sterk SQL-kunnskap: SQL er fortsatt databasespråket. ETL-utviklere må skrive effektive spørringer for å trekke ut og transformere data nøyaktig og raskt.
- Erfaring med ETL-verktøy: Praktisk erfaring med ETL-plattformer som Informatica, Talend eller Airflow sikrer at du kan bygge robuste og skalerbare pipelines uten å finne opp hjulet på nytt.
- Datamodellering: ETL-utviklere må forstå hvordan data er strukturert. Kunnskap om hvordan man utformer skjemaer som stjerne- og snøfnuggmodeller sikrer at data organiseres effektivt for rapportering og analyse.
- Skriptspråk: Språk som Python eller Bash er avgjørende for å bygge tilpassede skript, automatisering og integrasjoner utover det ETL-verktøyene tilbyr uten videre.
- Skytjenester: Overgangen til skyen akselererer på grunn av skalerbarhet, kostnadsbesparelser og administrerte tjenester. Ferdigheter i AWS Glue, Azure Data Factory eller Google Clouds Dataflow betyr at utvikleren kan jobbe i moderne, fleksible miljøer der infrastrukturen kan vokse i takt med virksomhetens behov.
- Problemløsning: ETL-arbeid er fullt av overraskelser - uventede dataavvik, mislykkede innlastinger og flaskehalser i ytelsen. Sterke problemløsningsferdigheter sikrer at utviklerne kan diagnostisere og løse problemer raskt uten at det går ut over driften.
- Ytelsesjustering: Etter hvert som datamengdene øker, blir effektiviteten viktig. Utviklere som vet hvordan man optimaliserer pipelines, bidrar til å redusere kostnader, spare tid og forbedre påliteligheten til hele dataøkosystemet.
En ETL-utvikler på toppnivå skriver også tydelig, vedlikeholdbar kode og forstår prinsippene for datastyring og sikkerhet.
Nice-to-have ferdigheter
Følgende ferdigheter er ikke obligatoriske, men de kan skille en god ETL-utvikler fra andre:
- Erfaring med strømming av data: Sanntidsanalyse blir stadig mer populært. Kunnskap om hvordan man arbeider med verktøy som Kafka eller Spark Streaming gjør det mulig for utviklere å bygge løsninger som reagerer umiddelbart på nye data.
- Kunnskap om API-er: Ettersom bedrifter integreres med utallige tredjepartsplattformer, blir API-kunnskap en betydelig fordel for sømløs integrering av ulike datakilder.
- Containerization: Verktøy som Docker og Kubernetes gjør ETL-distribusjoner mer portable og robuste, og hjelper organisasjoner med å administrere miljøer mer effektivt.
- Kompetanse innen datalagring: En dyp forståelse av datalagre som Snowflake, Redshift eller BigQuery gjør det mulig for utviklere å optimalisere innlasting og spørring av massive datasett.
- DevOps og CI/CD: Automatiserte distribusjoner og testrørledninger er i ferd med å bli standard innen datateknikk, noe som sikrer raskere og mer pålitelige oppdateringer av ETL-prosesser.
- Business Intelligence-integrasjon: Utviklere som tilpasser pipelines med rapporteringsverktøy som Tableau, Power BI eller Looker, tilfører enda mer verdi ved å muliggjøre sømløs tilgang til rene, strukturerte data.
Disse tilleggsfunksjonene kan gi betydelig verdi etter hvert som databehovene dine blir mer sofistikerte.
Intervjuspørsmål og eksempler på svar
Her er noen gjennomtenkte spørsmål som kan hjelpe deg med å vurdere kandidatene:
1. Kan du beskrive den mest komplekse ETL-pipelinen du har bygget?
Se etter: Størrelse på datasett, antall transformasjoner, feilhåndteringsstrategier.
Eksempel på svar: Jeg bygget en pipeline som hentet ut data om brukerhendelser fra flere apper, renset og sammenstilte dataene, beriket dem med tredjepartsinformasjon og lastet dem inn i Redshift. Jeg optimaliserte lastytelsen ved å partisjonere data og brukte AWS Glue for orkestrering.
2. Hvordan sikrer du datakvaliteten gjennom hele ETL-prosessen?
Se etter: Datavalideringsmetoder, avstemmingstrinn, feillogging.
Eksempel på svar: Jeg implementerer kontrollpunkter på hvert trinn, bruker dataprofileringsverktøy, logger avvik automatisk og setter opp varsler for terskelverdier som brytes.
3. Hvordan kan du optimalisere en ETL-jobb som går for sakte?
Se etter: Partisjonering, parallellprosessering, spørringsoptimalisering og maskinvaretuning.
Eksempel på svar: Jeg begynner med å analysere kjøringsplaner for spørringer, deretter refaktoriserer jeg transformasjoner for effektivitet, introduserer inkrementelle belastninger og skalerer om nødvendig opp beregningsressurser.
4. Hvordan håndterer du skjema-endringer i kildedata?
Se etter: Strategier for tilpasningsevne og robusthet.
Eksempel på svar: Jeg bygger inn skjemavalidering i pipelinen, bruker versjonskontroll for skjemauppdateringer og utformer ETL-jobber slik at de tilpasser seg dynamisk eller mislykkes på en elegant måte ved hjelp av varsler.
5. Hva er din erfaring med skybaserte ETL-verktøy?
Vi ser etter: Praktisk erfaring i stedet for bare teoretisk kunnskap.
Eksempel på svar: Jeg har brukt AWS Glue og Azure Data Factory i utstrakt grad, og har designet serverløse rørledninger og utnyttet integrerte integrasjoner med lagrings- og databehandlingstjenester.
6. Hvordan vil du utforme en ETL-prosess for å håndtere både full belastning og inkrementell belastning?
Eksempel på svar: For full innlasting utformer jeg ETL-en slik at den trunkerer og laster inn måltabellene på nytt, noe som passer for små til mellomstore datasett. For inkrementelle innlastinger implementerer jeg CDC-mekanismer (Change Data Capture), enten via tidsstempler, versjonsnumre eller databasetriggere. I et PostgreSQL-oppsett kan jeg for eksempel utnytte logiske replikasjonsspor for å hente bare de endrede radene siden forrige synkronisering.
7. Hva ville du gjort for å feilsøke en datapipeline som tidvis feiler?
Eksempel på svar: Først går jeg gjennom pipeline-loggene for å oppdage mønstre, for eksempel tidsbaserte feil eller dataavvik. Deretter isolerer jeg oppgaven som feiler - hvis det er et transformasjonstrinn, kjører jeg det på nytt med eksempeldata lokalt. Jeg setter ofte opp nye forsøk med eksponentiell backoff, og varsler via verktøy som PagerDuty for å sikre rask respons på feil.
8. Kan du forklare forskjellene mellom batchprosessering og sanntidsprosessering, og når du ville valgt det ene fremfor det andre?
Eksempel på svar: Batchbehandling innebærer å samle inn data over tid og behandle dem i bulk, noe som er perfekt for rapporteringssystemer som ikke trenger innsikt i sanntid, for eksempel salgsrapporter på slutten av dagen. Sanntidsbehandling ved hjelp av teknologier som Apache Kafka eller AWS Kinesis er avgjørende for brukstilfeller som svindeloppdagelse eller anbefalingsmotorer der millisekunder er avgjørende.
9. Hvordan håndterer du avhengigheter mellom flere ETL-jobber?
Eksempel på svar: Jeg bruker orkestreringsverktøy som Apache Airflow, der jeg definerer Directed Acyclic Graphs (DAGs) for å uttrykke jobbavhengigheter. En DAG kan for eksempel spesifisere at "extract"-oppgaven må være fullført før "transform" begynner. Jeg bruker også Airflows sensormekanismer for å vente på eksterne utløsere eller oppstrøms datatilgjengelighet.
10. Hvordan vil du sikre sensitive data under ETL-prosessen i et skymiljø?
Eksempel på svar: Jeg krypterer data både i hvile og i transitt, og bruker verktøy som AWS KMS for krypteringsnøkler. Jeg håndhever strenge IAM-policyer som sikrer at bare autoriserte ETL-jobber og -tjenester får tilgang til sensitive data. I pipelines maskerer eller tokeniserer jeg sensitive felt som PII (personlig identifiserbar informasjon) og vedlikeholder detaljerte revisjonslogger for å overvåke tilgang og bruk.
Sammendrag
Å ansette en ETL-utvikler handler om mer enn bare å finne noen som kan flytte data fra punkt A til punkt B. Det handler om å finne en fagperson som forstår nyansene i datakvalitet, ytelse og skiftende forretningsbehov. Vi ser etter kandidater med et sterkt teknisk fundament, praktisk erfaring med moderne verktøy og en proaktiv tilnærming til problemløsning. Ideelt sett vil din nye ETL-utvikler ikke bare vedlikeholde datastrømmene dine, men også kontinuerlig forbedre dem, slik at organisasjonens data alltid er pålitelige, skalerbare og klare til bruk.
