NEW
Proxify is bringing transparency to tech team performance based on research conducted at Stanford. An industry first, built for engineering leaders.
Learn more













ETL developers build the pipelines that move and transform raw data into usable formats for business intelligence, analytics, and machine learning. This guide walks you through everything you need to know to hire top ETL talent who will help your organization leverage data effectively.
About ETL Development
ETL development is at the heart of data engineering. It involves extracting data from various sources, transforming it to meet business needs, and loading it into a storage solution like a data warehouse or a data lake.
Today's ETL developers work with tools like Apache Airflow, Talend, Informatica, Azure Data Factory, and dbt (data build tool). They often code in SQL, Python, or Java, and increasingly use cloud-based services from AWS, Azure, and Google Cloud.
An experienced ETL developer not only ensures that data is reliably moved but also that it is clean, optimized, and ready for downstream use cases such as dashboards, reporting, and predictive modeling.
ETL vs. ELT
While ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) serve similar purposes in data integration, the order of operations and ideal use cases differ significantly. In traditional ETL workflows, data is transformed before it’s loaded into the destination system—ideal for on-premise environments and when transformations are complex or sensitive.
ELT, on the other hand, flips this order by first loading raw data into a target system—usually a modern cloud data warehouse like Snowflake, BigQuery, or Redshift—and then transforming it in place.
This approach leverages the scalable compute power of cloud platforms to handle large datasets more efficiently and simplifies pipeline architecture. Choosing between ETL and ELT often comes down to infrastructure, data volume, and specific business requirements.
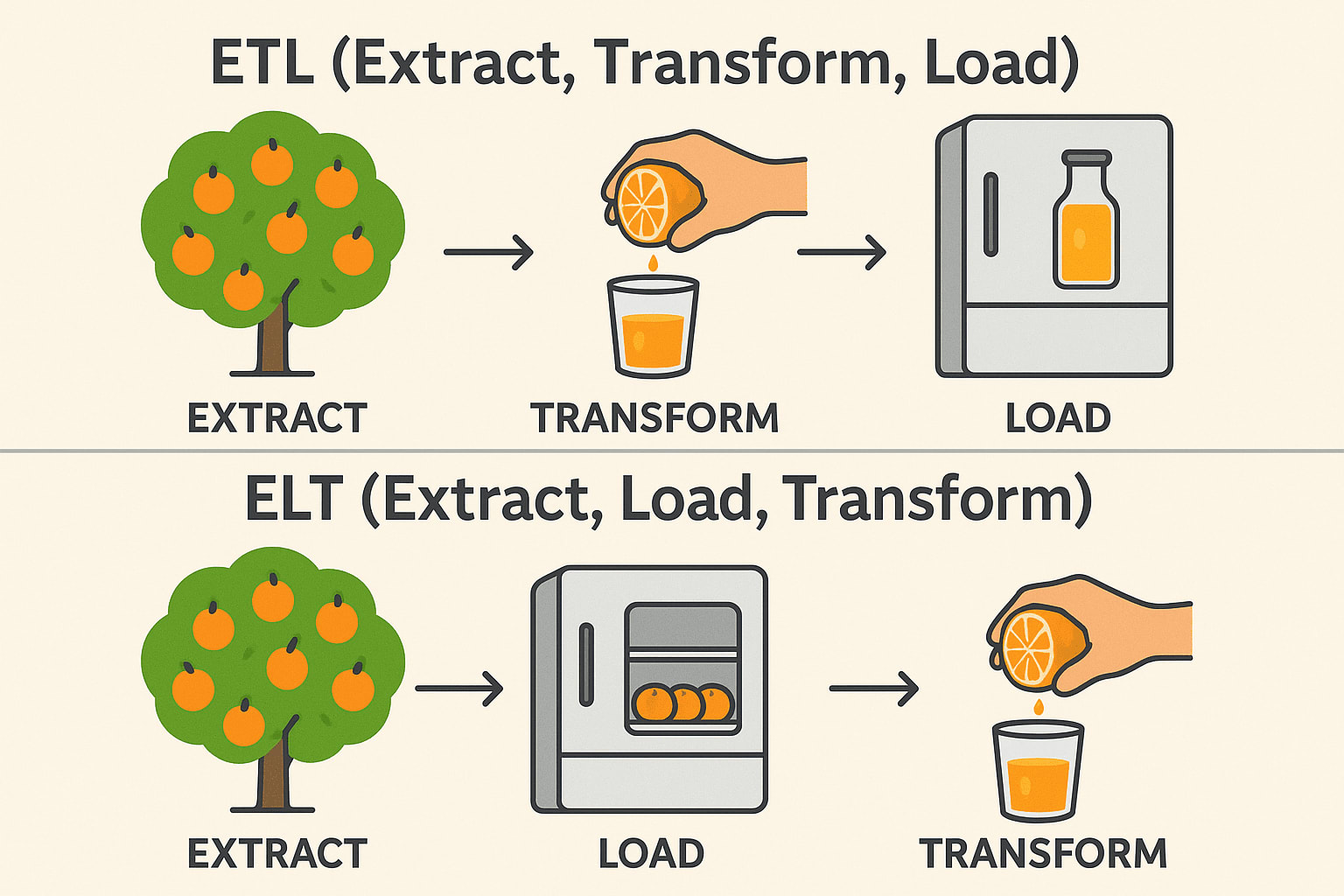
ETL (Extract → Transform → Load)
Extract: Pick oranges from the tree (Collect raw data from databases, APIs, or files). Transform: Squeeze them into juice before storing (Clean, filter, and format the data). Load: Store the ready-made juice in the fridge (Save structured data in a data warehouse). Commonly used in: Finance & Healthcare (Data must be clean before storage).
ELT (Extract → Load → Transform)
Extract: Pick oranges from the tree (Collect raw data from databases, APIs, or files). Load: Store the whole oranges in the fridge first (Save raw data in a data lake or cloud warehouse). Transform: Make juice when needed (Process and analyze data later). Commonly used in: Big Data & Cloud (Faster, scalable transformations). Tech stack: Snowflake, BigQuery, Databricks, AWS Redshift.
Industries and applications
ETL developers are indispensable across multiple industries, including:
- Finance: Consolidating transaction data for reporting and fraud detection.
- Healthcare: Integrating patient records across different systems for analysis.
- Retail & eCommerce: Centralizing customer and sales data for targeted marketing and inventory management.
- Telecommunications: Aggregating usage data to inform service improvements.
- Technology: Building reliable data backbones for SaaS platforms and AI models.
No matter the industry, businesses increasingly rely on accurate, timely data, making skilled ETL developers a critical asset.
Must-have skills for ETL Developers
When hiring an ETL developer, prioritize candidates who demonstrate these core skills:
- Strong SQL Knowledge: SQL remains the lingua franca of databases. ETL developers must write efficient queries to extract and transform data accurately and quickly.
- Experience with ETL tools: Practical experience with ETL platforms like Informatica, Talend, or Airflow ensures they can build robust and scalable pipelines without reinventing the wheel.
- Data modeling: ETL developers must understand how data is structured. Knowing how to design schemas like star and snowflake models ensures data is organized efficiently for reporting and analytics.
- Scripting languages: Languages like Python or Bash are crucial for building custom scripts, automation, and integrations beyond what ETL tools offer out of the box.
- Cloud Data Services: The shift to the cloud is accelerating because of scalability, cost savings, and managed services. Proficiency in AWS Glue, Azure Data Factory, or Google Cloud’s Dataflow means the developer can work in modern, flexible environments where infrastructure can grow with your business needs.
- Problem-solving: ETL work is full of surprises—unexpected data anomalies, failed loads, and performance bottlenecks. Strong problem-solving skills ensure developers can diagnose and fix issues quickly without derailing operations.
- Performance tuning: As data volumes increase, efficiency matters. Developers who know how to optimize pipelines help reduce costs, save time, and improve the reliability of the entire data ecosystem.
A top-tier ETL developer also writes clear, maintainable code and understands the principles of data governance and security.
Nice-to-have skills
While not mandatory, the following skills can set great ETL developers apart:
- Experience with streaming data: Real-time analytics is becoming more popular. Knowing how to work with tools like Kafka or Spark Streaming enables developers to build solutions that react instantly to new data.
- Knowledge of APIs: As businesses integrate with countless third-party platforms, API fluency becomes a significant advantage for seamlessly integrating diverse data sources.
- Containerization: Tools like Docker and Kubernetes make ETL deployments more portable and resilient, helping organizations manage environments more efficiently.
- Data warehousing expertise: A deep understanding of warehouses like Snowflake, Redshift, or BigQuery allows developers to optimize the loading and querying of massive datasets.
- DevOps and CI/CD: Automated deployments and testing pipelines are becoming standard in data engineering, ensuring faster, more reliable updates to ETL processes.
- Business Intelligence integration: Developers who align their pipelines with reporting tools like Tableau, Power BI, or Looker add even more value by enabling seamless access to clean, structured data.
These additional capabilities can provide significant value as your data needs grow more sophisticated.
Interview questions and example answers
Here are some thoughtful questions to help you assess candidates:
1. Can you describe the most complex ETL pipeline you’ve built?
Look for: Size of datasets, number of transformations, error handling strategies.
Sample answer: I built a pipeline that extracted user event data from multiple apps, cleaned and joined the data, enriched it with third-party information, and loaded it into Redshift. I optimized load performance by partitioning data and used AWS Glue for orchestration.
2. How do you ensure data quality throughout the ETL process?
Look for: Data validation methods, reconciliation steps, error logging.
Sample answer: I implement checkpoints at each stage, use data profiling tools, log anomalies automatically, and set up alerts for thresholds being breached.
3. How would you optimize an ETL job that’s running too slowly?
Look for: Partitioning, parallel processing, query optimization, and hardware tuning.
Sample answer: I start by analyzing query execution plans, then refactor transformations for efficiency, introduce incremental loads, and if necessary, scale up compute resources.
4. How do you handle schema changes in source data?
Look for: Strategies for adaptability and robustness.
Sample answer: I build schema validation into the pipeline, use version control for schema updates, and design ETL jobs to adapt dynamically or fail gracefully with alerts.
5. What’s your experience with cloud-based ETL tools?
Look for: Practical experience rather than just theoretical knowledge.
Sample answer: I've used AWS Glue and Azure Data Factory extensively, designing serverless pipelines and leveraging native integrations with storage and compute services.
6. How would you design an ETL process to handle both full loads and incremental loads?
Sample answer: For full loads, I design the ETL to truncate and reload the target tables, suitable for small to medium datasets. For incremental loads, I implement change data capture (CDC) mechanisms, either via timestamps, version numbers, or database triggers. For example, in a PostgreSQL setup, I might leverage logical replication slots to pull only the changed rows since the last sync.
7. What steps would you take to troubleshoot a data pipeline that intermittently fails?
Sample answer: First, I review the pipeline logs to detect patterns, such as time-based failures or data anomalies. Then, I isolate the failing task—if it's a transformation step, I'll re-run it with sample data locally. I often set up retries with exponential backoff, and alerts via tools like PagerDuty to ensure a timely response to failures.
8. Can you explain the differences between batch processing and real-time processing, and when you would choose one over the other?
Sample answer: Batch processing involves collecting data over time and processing it in bulk, perfect for reporting systems that don't need real-time insights, like end-of-day sales reports. Real-time processing, using technologies like Apache Kafka or AWS Kinesis, is critical for use cases like fraud detection or recommendation engines where milliseconds matter.
9. How do you manage dependencies between multiple ETL jobs?
Sample answer: I use orchestration tools like Apache Airflow, where I define Directed Acyclic Graphs (DAGs) to express job dependencies. For instance, a DAG might specify that the 'extract' task must complete before 'transform' begins. I also use Airflow’s sensor mechanisms to wait for external triggers or upstream data availability.
10. In a cloud environment, how would you secure sensitive data during the ETL process?
Sample answer: I encrypt data both at rest and in transit, using tools like AWS KMS for encryption keys. I enforce strict IAM policies, ensuring that only authorized ETL jobs and services can access sensitive data. In pipelines, I mask or tokenize sensitive fields like PII (Personally Identifiable Information) and maintain detailed audit logs to monitor access and usage.
Summary
Hiring an ETL developer is about more than just finding someone who can move data from point A to point B. It's about finding a professional who understands the nuances of data quality, performance, and evolving business needs. Look for candidates with a strong technical foundation, practical experience with modern tools, and a proactive approach to problem-solving. Ideally, your new ETL developer will not only maintain your data flows but also continuously improve them, ensuring your organization’s data is always trustworthy, scalable, and ready for action.
