NEW
Proxify is bringing transparency to tech team performance based on research conducted at Stanford. An industry first, built for engineering leaders.
Learn more













Les développeurs ETL construisent les pipelines qui déplacent et transforment les données brutes dans des formats utilisables pour la veille stratégique, l'analyse et l'apprentissage automatique. Ce guide vous explique tout ce que vous devez savoir pour embaucher les meilleurs talents ETL qui aideront votre organisation à exploiter efficacement les données.
A propos du développement ETL
Le développement ETL est au cœur de l'ingénierie des données. Il s'agit d'extraire des données de différentes sources, de les transformer pour répondre aux besoins de l'entreprise et de les charger dans une solution de stockage telle qu'un entrepôt de données ou un lac de données.
Les développeurs ETL d'aujourd'hui travaillent avec des outils comme Apache Airflow, Talend, Informatica, Azure Data Factory et dbt (outil de construction de données). Ils codent souvent en SQL, Python ou Java, et utilisent de plus en plus des services basés sur le cloud tels que AWS, Azure et Google Cloud.
Un développeur ETL expérimenté s'assure non seulement que les données sont déplacées de manière fiable, mais aussi qu'elles sont propres, optimisées et prêtes pour les utilisations en aval telles que les tableaux de bord, les rapports et la modélisation prédictive.
ETL vs. ELT
Bien que l'ETL (Extract, Transform, Load) et l'ELT (Extract, Load, Transform) servent des objectifs similaires dans l'intégration des données, l'ordre des opérations et les cas d'utilisation idéaux diffèrent de manière significative. Dans les flux de travail ETL traditionnels, les données sont transformées avant d'être chargées dans le système de destination, ce qui est idéal pour les environnements sur site et lorsque les transformations sont complexes ou sensibles.
Les ELT, en revanche, inversent cet ordre en chargeant d'abord des données brutes dans un système cible - généralement un entrepôt de données en nuage moderne comme Snowflake, BigQuery, ou Redshift- et en les transformant ensuite sur place.
Cette approche tire parti de la puissance de calcul évolutive des plateformes en nuage pour traiter plus efficacement les grands ensembles de données et simplifier l'architecture des pipelines. Le choix entre ETL et ELT dépend souvent de l'infrastructure, du volume de données et des exigences spécifiques de l'entreprise.
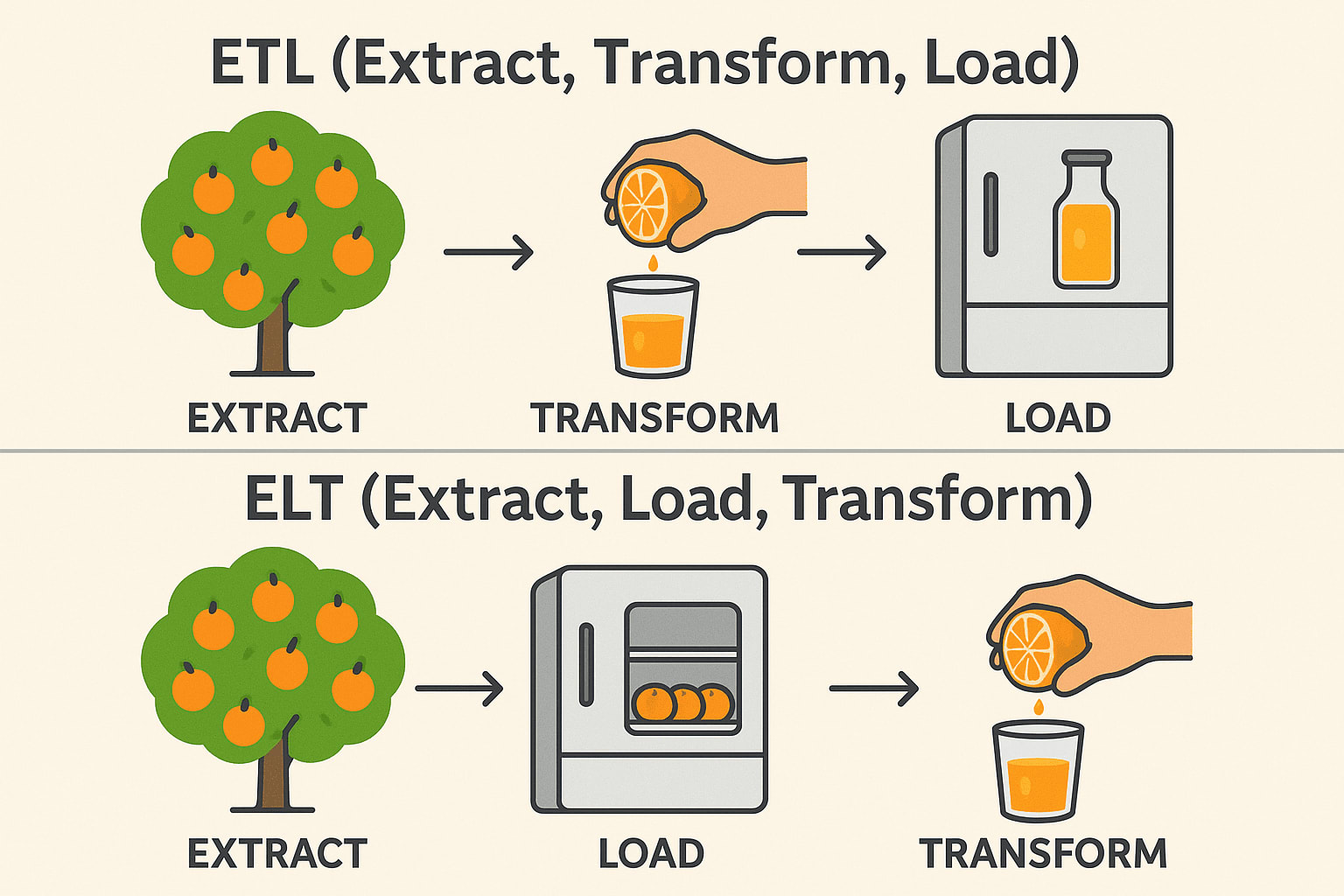
ETL (Extract → Transform → Load)
Extraire: Cueillir des oranges sur l'arbre (collecter des données brutes à partir de bases de données, d'API ou de fichiers). Transformation: Les presser en jus avant de les stocker (nettoyer, filtrer et formater les données). Load: Conservez le jus de fruits prêt à l'emploi dans le réfrigérateur (sauvegardez les données structurées dans un entrepôt de données). Couramment utilisé dans: Finance et santé (les données doivent être propres avant d'être stockées).
ELT (Extract → Load → Transform)
Extraire: Cueillir des oranges sur l'arbre (collecter des données brutes à partir de bases de données, d'API ou de fichiers). Load: Conservez d'abord les oranges entières au réfrigérateur (sauvegardez les données brutes dans un lac de données ou un entrepôt en nuage). Transformer: Faire du jus quand c'est nécessaire (Traiter et analyser les données plus tard). Utilisé couramment dans: Big Data & Cloud (transformations plus rapides et évolutives). Pile technologique: Snowflake, BigQuery, Databricks, AWS Redshift.
Industries et applications
Les développeurs ETL sont indispensables dans de nombreux secteurs d'activité, notamment :
- Finance: Consolidation des données de transaction pour le reporting et la détection des fraudes.
- Santé: Intégration des dossiers des patients dans différents systèmes à des fins d'analyse.
- Retail & eCommerce: Centralisation des données clients et ventes pour un marketing ciblé et une gestion des stocks.
- Télécommunications: Agrégation des données d'utilisation pour améliorer les services.
- Technologie: Construire des backbones de données fiables pour les plateformes SaaS et les modèles d'IA.
Quel que soit leur secteur d'activité, les entreprises dépendent de plus en plus de données précises et actualisées, ce qui fait des développeurs ETL compétents un atout essentiel.
Compétences indispensables pour les développeurs ETL
Lorsque vous recrutez un développeur ETL, donnez la priorité aux candidats qui démontrent ces compétences de base :
- Fortes connaissances en SQL : SQL reste la lingua franca des bases de données. Les développeurs ETL doivent écrire des requêtes efficaces pour extraire et transformer les données avec précision et rapidité.
- Expérience des outils ETL : Une expérience pratique des plateformes ETL comme Informatica, Talend, ou Airflow permet de construire des pipelines robustes et évolutifs sans avoir à réinventer la roue.
- Les développeurs ETL doivent comprendre comment les données sont structurées. Savoir concevoir des schémas tels que les modèles en étoile et en flocon de neige permet de s'assurer que les données sont organisées efficacement pour le reporting et l'analyse.
- Les langages comme Python ou Bash sont cruciaux pour la création de scripts personnalisés, l'automatisation et les intégrations au-delà de ce que les outils ETL offrent en standard.
- Cloud Data Services : Le passage au cloud s'accélère en raison de l'évolutivité, de la réduction des coûts et des services gérés. La maîtrise de AWS Glue, Azure Data Factory, ou Google Cloud's Dataflow signifie que le développeur peut travailler dans des environnements modernes et flexibles où l'infrastructure peut évoluer avec les besoins de l'entreprise.
- Résolution de problèmes : Le travail d'ETL est plein de surprises - anomalies de données inattendues, chargements ratés et goulots d'étranglement au niveau des performances. De solides compétences en matière de résolution de problèmes permettent aux développeurs de diagnostiquer et de résoudre rapidement les problèmes sans perturber les opérations.
- Réglage des performances : L'augmentation des volumes de données donne de l'importance à l'efficacité. Les développeurs qui savent comment optimiser les pipelines aident à réduire les coûts, à gagner du temps et à améliorer la fiabilité de l'ensemble de l'écosystème des données.
Un développeur ETL de haut niveau écrit également un code clair et facile à maintenir et comprend les principes de la gouvernance et de la sécurité des données.
Compétences indispensables
Bien qu'elles ne soient pas obligatoires, les compétences suivantes peuvent distinguer les développeurs ETL :
- Expérience en matière de flux de données : l'analyse en temps réel devient de plus en plus populaire. Savoir travailler avec des outils comme Kafka ou Spark Streaming permet aux développeurs de construire des solutions qui réagissent instantanément aux nouvelles données.
- Connaissance des API : Les entreprises s'intégrant à d'innombrables plateformes tierces, la maîtrise des API devient un avantage significatif pour l'intégration transparente de diverses sources de données.
- Les outils comme Docker et Kubernetes rendent les déploiements ETL plus portables et résilients, aidant les organisations à gérer les environnements plus efficacement.
- Une connaissance approfondie des entrepôts de données tels que Snowflake, Redshift ou BigQuery permet aux développeurs d'optimiser le chargement et l'interrogation d'énormes ensembles de données.
- DevOps et CI/CD: Les déploiements automatisés et les pipelines de test deviennent la norme dans l'ingénierie des données, assurant des mises à jour plus rapides et plus fiables des processus ETL.
- Les développeurs qui alignent leurs pipelines avec des outils de reporting comme Tableau, Power BI, ou Looker ajoutent encore plus de valeur en permettant un accès transparent à des données propres et structurées.
Ces capacités supplémentaires peuvent s'avérer très utiles lorsque vos besoins en matière de données deviennent de plus en plus sophistiqués.
Questions d'entretien et exemples de réponses
Voici quelques questions pour vous aider à évaluer les candidats :
1. Pouvez-vous décrire le pipeline ETL le plus complexe que vous ayez construit ?
Taille des ensembles de données, nombre de transformations, stratégies de gestion des erreurs.
Exemple de réponse: J'ai construit un pipeline qui extrait des données d'événements d'utilisateurs à partir de plusieurs applications, nettoie et joint les données, les enrichit avec des informations tierces et les charge dans Redshift. J'ai optimisé les performances de chargement en partitionnant les données et en utilisant AWS Glue pour l'orchestration.
2. Comment assurez-vous la qualité des données tout au long du processus ETL ?
Méthodes de validation des données, étapes de réconciliation, enregistrement des erreurs.
Exemple de réponse: Je mets en place des points de contrôle à chaque étape, j'utilise des outils de profilage des données, j'enregistre automatiquement les anomalies et je mets en place des alertes en cas de dépassement des seuils.
3. Comment optimiser un travail ETL qui tourne trop lentement ?
Look for: Partitioning, parallel processing, query optimization, and hardware tuning.
Exemple de réponse: Je commence par analyser les plans d'exécution des requêtes, puis je remanie les transformations pour les rendre plus efficaces, j'introduis des charges incrémentielles et, si nécessaire, j'augmente les ressources de calcul.
4. Comment gérez-vous les changements de schéma dans les données sources ?
Rechercher: Stratégies d'adaptabilité et de robustesse.
Exemple de réponse: J'intègre la validation des schémas dans le pipeline, j'utilise le contrôle de version pour les mises à jour des schémas et je conçois les tâches ETL pour qu'elles s'adaptent dynamiquement ou qu'elles échouent de manière gracieuse grâce à des alertes.
5. Quelle est votre expérience des outils ETL basés sur le cloud ?
Recherchez: Une expérience pratique plutôt qu'une simple connaissance théorique.
Exemple de réponse: J'ai beaucoup utilisé AWS Glue et Azure Data Factory, en concevant des pipelines sans serveur et en exploitant les intégrations natives avec les services de stockage et de calcul.
6. Comment concevez-vous un processus ETL pour gérer à la fois des charges complètes et des charges incrémentielles ?
Exemple de réponse: Pour les chargements complets, je conçois l'ETL pour tronquer et recharger les tables cibles, ce qui convient aux ensembles de données de petite à moyenne taille. Pour les chargements incrémentaux, je mets en œuvre des mécanismes de capture des données de changement (CDC), soit par le biais d'horodatages, de numéros de version ou de déclencheurs de base de données. Par exemple, dans une installation PostgreSQL, je pourrais utiliser les slots de réplication logique pour extraire uniquement les lignes modifiées depuis la dernière synchronisation.
7. Quelles mesures prendriez-vous pour dépanner un pipeline de données qui échoue de façon intermittente ?
Exemple de réponse: Tout d'abord, j'examine les journaux du pipeline pour détecter des schémas, tels que des défaillances temporelles ou des anomalies de données. Ensuite, j'isole la tâche défaillante - s'il s'agit d'une étape de transformation, je la réexécute localement avec un échantillon de données. Je mets souvent en place des tentatives avec un backoff exponentiel, et des alertes via des outils comme PagerDuty pour assurer une réponse rapide aux échecs.
8. Pouvez-vous expliquer les différences entre le traitement par lots et le traitement en temps réel, et quand vous choisiriez l'un plutôt que l'autre ?
Exemple de réponse: Le traitement par lots consiste à collecter des données au fil du temps et à les traiter en masse, ce qui est parfait pour les systèmes de reporting qui n'ont pas besoin d'informations en temps réel, comme les rapports de vente de fin de journée. Le traitement en temps réel, en utilisant des technologies comme Apache Kafka ou AWS Kinesis, est essentiel pour des cas d'utilisation comme la détection de la fraude ou les moteurs de recommandation où les millisecondes comptent.
9. Comment gérez-vous les dépendances entre plusieurs travaux ETL ?
Exemple de réponse: J'utilise des outils d'orchestration comme Apache Airflow, où je définis des graphes acycliques dirigés (DAG) pour exprimer les dépendances des tâches. Par exemple, un DAG peut spécifier que la tâche "extract" doit être terminée avant que la tâche "transform" ne commence. J'utilise également les mécanismes de capteurs d'Airflow pour attendre des déclencheurs externes ou la disponibilité de données en amont.
10. Dans un environnement en nuage, comment sécuriser les données sensibles pendant le processus ETL ?
Exemple de réponse: Je crypte les données au repos et en transit, en utilisant des outils comme AWS KMS pour les clés de cryptage. Je mets en œuvre des politiques IAM strictes, en veillant à ce que seuls les travaux et services ETL autorisés puissent accéder aux données sensibles. Dans les pipelines, je masque ou tokenise les champs sensibles comme les PII (Personally Identifiable Information) et je maintiens des logs d'audit détaillés pour contrôler l'accès et l'utilisation.
Résumé
Embaucher un développeur ETL ne consiste pas seulement à trouver quelqu'un capable de déplacer des données d'un point A à un point B. Il s'agit de trouver un professionnel qui comprend les nuances de la qualité des données, des performances et de l'évolution des besoins de l'entreprise. Nous recherchons des candidats ayant de solides bases techniques, une expérience pratique des outils modernes et une approche proactive de la résolution des problèmes. Idéalement, votre nouveau développeur ETL ne se contentera pas de maintenir vos flux de données, mais les améliorera en permanence, afin que les données de votre organisation soient toujours fiables, évolutives et prêtes à l'emploi.
