NEW
Proxify is bringing transparency to tech team performance based on research conducted at Stanford. An industry first, built for engineering leaders.
Learn more













ETL-ontwikkelaars bouwen de pijplijnen die ruwe gegevens verplaatsen en transformeren in bruikbare formaten voor business intelligence, analytics en machine learning. Deze gids vertelt je alles wat je moet weten om ETL-talent aan te werven dat jouw organisatie zal helpen om gegevens effectief te gebruiken.
Over ETL Ontwikkeling
ETL-ontwikkeling is het hart van data-engineering. Het gaat om het extraheren van gegevens uit verschillende bronnen, het transformeren ervan om aan de bedrijfsbehoeften te voldoen en het laden ervan in een opslagoplossing zoals een datawarehouse of een data lake.
ETL-ontwikkelaars werken tegenwoordig met tools zoals Apache Airflow, Talend, Informatica, Azure Data Factory en dbt (data build tool). Ze coderen vaak in SQL, Python of Java en maken steeds meer gebruik van cloud-gebaseerde diensten van AWS, Azure en Google Cloud.
Een ervaren ETL-ontwikkelaar zorgt er niet alleen voor dat gegevens betrouwbaar worden verplaatst, maar ook dat ze schoon en geoptimaliseerd zijn en klaar voor downstream gebruik, zoals dashboards, rapportage en voorspellende modellen.
ETL vs. ELT
Hoewel ETL (Extract, Transform, Load) en ELT (Extract, Load, Transform) vergelijkbare doelen dienen bij gegevensintegratie, verschillen de volgorde van de bewerkingen en de ideale gebruikssituaties aanzienlijk. In traditionele ETL workflows worden gegevens getransformeerd voordat ze in het bestemmingssysteem worden geladen - ideaal voor on-premise omgevingen en wanneer transformaties complex of gevoelig zijn.
ELT daarentegen draait deze volgorde om door eerst ruwe gegevens in een doelsysteem te laden - meestal een modern cloud datawarehouse zoals Snowflake, BigQuery, of Redshift- en deze vervolgens ter plekke te transformeren.
Deze aanpak maakt gebruik van de schaalbare rekenkracht van cloudplatforms om efficiënter om te gaan met grote datasets en vereenvoudigt de pijplijnarchitectuur. De keuze tussen ETL en ELT hangt vaak af van de infrastructuur, het datavolume en de specifieke bedrijfsvereisten.
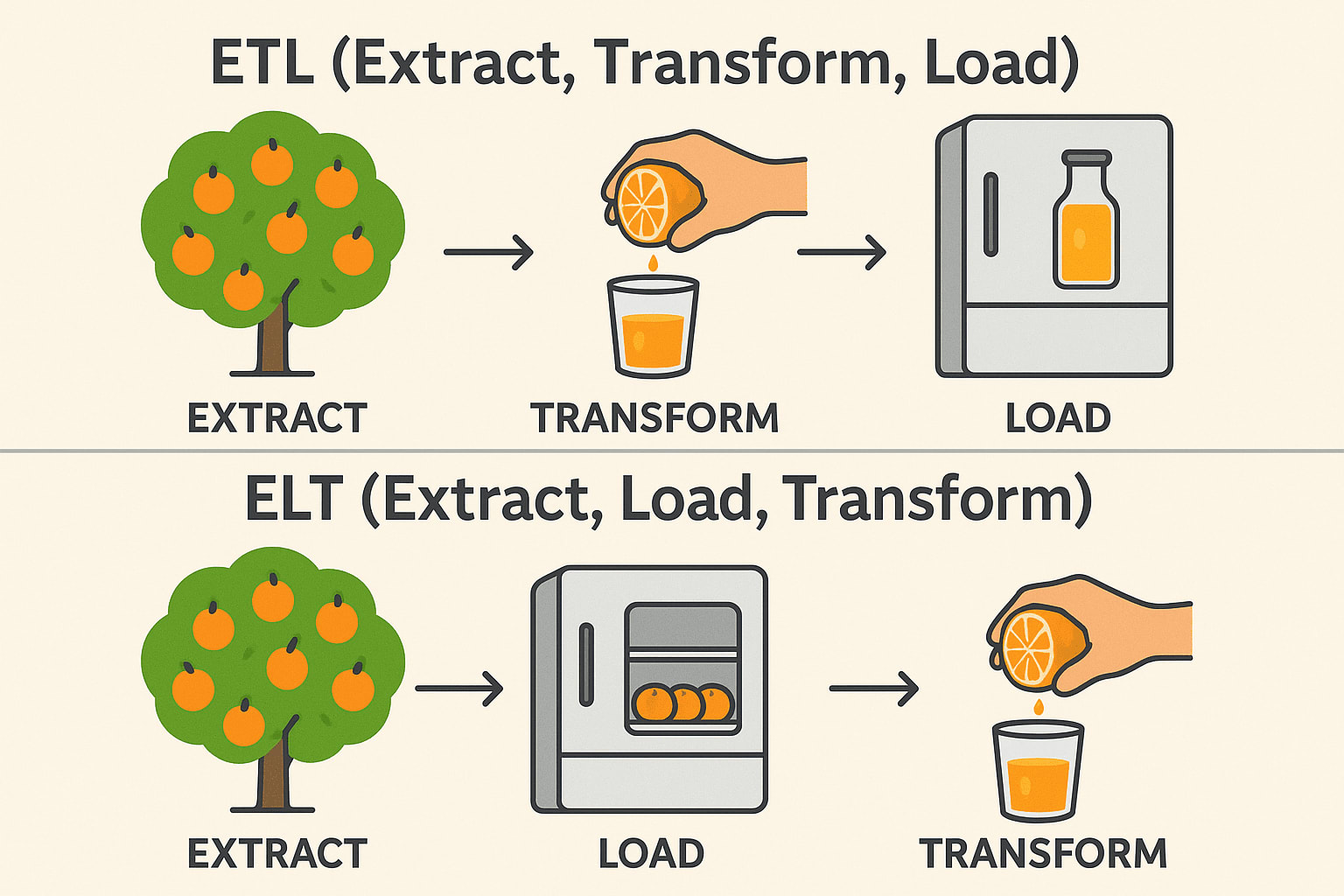
ETL proces analogie](https://res.cloudinary.com/proxify-io/image/upload/v1/cms/images/gallery/0unptWOm9HjdGtQl6odXeDvx1qDTwu5owNhSpCtq.png)
ETL (Extraheren → Transformeren → Laden)
Extract: Pluk sinaasappels uit de boom (Verzamel ruwe gegevens uit databases, API's of bestanden). Transformeer: Pers ze uit tot sap voordat je ze opslaat (Reinig, filter en formatteer de gegevens). Load: Bewaar de kant-en-klare sapjes in de koelkast (Sla gestructureerde gegevens op in een datawarehouse). Vaak gebruikt in: Financiën en gezondheidszorg (gegevens moeten schoon zijn voordat ze worden opgeslagen).
ELT (Extraheren → Laden → Transformeren)
Extract: Pluk sinaasappels uit de boom (Verzamel ruwe gegevens uit databases, API's of bestanden). Load: Bewaar de hele sinaasappels eerst in de koelkast (Sla ruwe data op in een data lake of cloud warehouse). Transformeer: Maak sap wanneer dat nodig is (Verwerk en analyseer gegevens later). Vaak gebruikt in: Big Data & Cloud (Snellere, schaalbare transformaties). Technische stapel: Snowflake, BigQuery, Databricks, AWS Redshift.
Industrieën en toepassingen
ETL-ontwikkelaars zijn onmisbaar in verschillende bedrijfstakken, waaronder:
- Finance: Consolideren van transactiegegevens voor rapportage en fraudedetectie.
- Gezondheidszorg: Het integreren van patiëntendossiers in verschillende systemen voor analyse.
- Retail & eCommerce: Centraliseren van klant- en verkoopgegevens voor gerichte marketing en voorraadbeheer.
- Telecommunicatie: Samenvoegen van gebruiksgegevens om de service te verbeteren.
- Technologie: Het bouwen van betrouwbare data backbones voor SaaS platforms en AI modellen.
Het maakt niet uit in welke branche, bedrijven vertrouwen in toenemende mate op nauwkeurige en tijdige gegevens, waardoor bekwame ETL-ontwikkelaars een essentieel onderdeel vormen.
Vereiste vaardigheden voor ETL-ontwikkelaars
Geef bij het aannemen van een ETL ontwikkelaar de voorkeur aan kandidaten die deze kernvaardigheden kunnen aantonen:
- Sterke SQL-kennis: SQL blijft de lingua franca van databases. ETL-ontwikkelaars moeten efficiënte queries schrijven om gegevens nauwkeurig en snel te extraheren en te transformeren.
- Ervaring met ETL-tools: Praktische ervaring met ETL-platforms zoals Informatica, Talend, of Airflow zorgt ervoor dat ze robuuste en schaalbare pijplijnen kunnen bouwen zonder het wiel opnieuw uit te vinden.
- Gegevensmodellering: ETL-ontwikkelaars moeten begrijpen hoe gegevens gestructureerd zijn. Weten hoe je schema's ontwerpt, zoals ster- en sneeuwvlokmodellen, zorgt ervoor dat gegevens efficiënt worden georganiseerd voor rapportage en analyse.
- Scripting talen: Talen zoals Python of Bash zijn cruciaal voor het bouwen van aangepaste scripts, automatisering en integraties die verder gaan dan wat ETL-tools out of the box bieden.
- Cloud Data Services: De verschuiving naar de cloud versnelt vanwege schaalbaarheid, kostenbesparingen en beheerde services. Bekwaamheid in AWS Glue, Azure Data Factory, of Google Cloud's Dataflow betekent dat de ontwikkelaar kan werken in moderne, flexibele omgevingen waar de infrastructuur kan meegroeien met uw zakelijke behoeften.
- Probleemoplossing: ETL-werk zit vol verrassingen - onverwachte afwijkingen in gegevens, mislukte ladingen en prestatieproblemen. Sterke probleemoplossende vaardigheden zorgen ervoor dat ontwikkelaars problemen snel kunnen diagnosticeren en oplossen zonder dat de werkzaamheden ontsporen.
- Performance tuning: Als datavolumes toenemen, is efficiëntie belangrijk. Ontwikkelaars die weten hoe ze pijplijnen moeten optimaliseren, helpen kosten te besparen, tijd te besparen en de betrouwbaarheid van het hele data-ecosysteem te verbeteren.
Een ETL ontwikkelaar van topniveau schrijft ook duidelijke, onderhoudbare code en begrijpt de principes van data governance en beveiliging.
Leuke vaardigheden
Hoewel het niet verplicht is, kunnen de volgende vaardigheden de beste ETL-ontwikkelaars onderscheiden:
- Ervaring met streaming data: Real-time analytics wordt steeds populairder. Als je weet hoe je met tools als Kafka of Spark Streaming moet werken, kun je als ontwikkelaar oplossingen bouwen die direct reageren op nieuwe gegevens.
- Kennis van API's: Aangezien bedrijven integreren met talloze platforms van derden, wordt API-vaardigheid een belangrijk voordeel voor het naadloos integreren van verschillende gegevensbronnen.
- Containerisatie: Tools zoals Docker en Kubernetes maken ETL implementaties draagbaarder en veerkrachtiger, en helpen organisaties omgevingen efficiënter te beheren.
- Data warehousing expertise: Een diepgaande kennis van warehouses zoals Snowflake, Redshift of BigQuery stelt ontwikkelaars in staat om het laden en opvragen van enorme datasets te optimaliseren.
- DevOps en CI/CD: Geautomatiseerde implementaties en testpijplijnen worden standaard in data-engineering en zorgen voor snellere, betrouwbaardere updates van ETL-processen.
- Business Intelligence-integratie: Ontwikkelaars die hun pijplijnen afstemmen op rapportagetools zoals Tableau, Power BI, of Looker voegen nog meer waarde toe door naadloze toegang tot schone, gestructureerde gegevens mogelijk te maken.
Deze extra mogelijkheden kunnen van grote waarde zijn naarmate uw gegevensbehoeften geavanceerder worden.
Interviewvragen en voorbeeldantwoorden
Hier zijn enkele doordachte vragen om u te helpen kandidaten te beoordelen:
1. Kun je de meest complexe ETL pijplijn beschrijven die je hebt gebouwd?
Let op: Grootte van datasets, aantal transformaties, foutafhandelingstrategieën.
Voorbeeldantwoord: Ik heb een pijplijn gebouwd die gegevens over gebruikersgebeurtenissen uit meerdere apps haalt, de gegevens opschoont en samenvoegt, verrijkt met informatie van derden en in Redshift laadt. Ik heb de laadprestaties geoptimaliseerd door gegevens te partitioneren en AWS Glue te gebruiken voor orkestratie.
2. Hoe garandeer je datakwaliteit tijdens het ETL proces?
Zoek naar: methoden voor gegevensvalidatie, afstemmingsstappen, foutregistratie.
Voorbeeld van antwoord: Ik implementeer controlepunten in elke fase, gebruik tools voor gegevensprofilering, log afwijkingen automatisch en stel waarschuwingen in voor drempels die worden overschreden.
3. Hoe zou je een ETL job optimaliseren die te traag draait?
Zoek naar: Partitionering, parallelle verwerking, query optimalisatie en hardware tuning.
Voorbeeld van een antwoord: Ik begin met het analyseren van plannen voor het uitvoeren van query's, vervolgens herfactureer ik transformaties voor efficiëntie, introduceer ik incrementele belastingen en schaal ik indien nodig rekenbronnen op.
4. Hoe gaat u om met schemawijzigingen in brondata?
Zoek naar: Strategieën voor aanpasbaarheid en robuustheid.
Voorbeeld van antwoord: Ik bouw schemavalidatie in de pijplijn in, gebruik versiebeheer voor schema-updates en ontwerp ETL-taken om dynamisch aan te passen of gracieus te falen met waarschuwingen.
5. Wat is je ervaring met cloud-gebaseerde ETL-tools?
Kijk naar: Praktische ervaring in plaats van alleen theoretische kennis.
Voorbeeld van een antwoord: Ik heb AWS Glue en Azure Data Factory uitgebreid gebruikt, waarbij ik serverloze pipelines heb ontworpen en gebruik heb gemaakt van native integraties met opslag- en computerservices.
6. Hoe zou je een ETL proces ontwerpen om zowel volledige ladingen als incrementele ladingen te verwerken?
Voorbeeld van antwoord: Voor volledige ladingen ontwerp ik de ETL om de doeltabellen te trunceren en opnieuw te laden, geschikt voor kleine tot middelgrote datasets. Voor incrementele ladingen implementeer ik mechanismen voor het vastleggen van veranderingsgegevens (CDC), via tijdstempels, versienummers of databasetriggers. In een PostgreSQL setup zou ik bijvoorbeeld gebruik kunnen maken van logische replicatie slots om alleen de gewijzigde rijen sinds de laatste synchronisatie op te halen.
7. Welke stappen zou u nemen om een gegevenspijplijn op te lossen die af en toe faalt?
Voorbeeld van een antwoord: Eerst bekijk ik de logbestanden van de pijplijn om patronen te ontdekken, zoals tijdsgebaseerde storingen of afwijkingen in de gegevens. Vervolgens isoleer ik de mislukte taak - als het een transformatiestap is, voer ik deze lokaal opnieuw uit met voorbeeldgegevens. Ik stel vaak retries in met exponentiële backoff en waarschuwingen via tools zoals PagerDuty om een tijdige reactie op fouten te garanderen.
8. Kunt u uitleggen wat de verschillen zijn tussen batchverwerking en real-time verwerking, en wanneer u het ene boven het andere zou verkiezen?
Voorbeeld van een antwoord: Bij batchverwerking worden gegevens in de loop van de tijd verzameld en in bulk verwerkt. Dit is perfect voor rapportagesystemen die geen realtime-inzichten nodig hebben, zoals verkooprapporten aan het einde van de dag. Real-time verwerking, met behulp van technologieën zoals Apache Kafka of AWS Kinesis, is van cruciaal belang voor use cases zoals fraudedetectie of aanbevelingsengines waarbij milliseconden van belang zijn.
9. Hoe beheer je afhankelijkheden tussen meerdere ETL jobs?
Voorbeeld van een antwoord: Ik gebruik orkestratieprogramma's zoals Apache Airflow, waarin ik Directed Acyclic Graphs (DAG's) definieer om taakafhankelijkheden uit te drukken. Een DAG zou bijvoorbeeld kunnen specificeren dat de 'extract' taak voltooid moet zijn voordat 'transform' begint. Ik gebruik ook de sensormechanismen van Airflow om te wachten op externe triggers of upstream beschikbaarheid van gegevens.
10. Hoe zou je in een cloudomgeving gevoelige gegevens beveiligen tijdens het ETL-proces?
Voorbeeld van een antwoord: Ik versleutel gegevens zowel in rust als in transit en gebruik tools zoals AWS KMS voor versleutelingscodes. Ik hanteer een strikt IAM-beleid, zodat alleen geautoriseerde ETL-taken en -services toegang hebben tot gevoelige gegevens. In pijplijnen maskeer of token ik gevoelige velden zoals PII (Persoonlijk Identificeerbare Informatie) en houd ik gedetailleerde auditlogs bij om toegang en gebruik te controleren.
Samenvatting
Bij het inhuren van een ETL-ontwikkelaar gaat het om meer dan alleen het vinden van iemand die gegevens van punt A naar punt B kan verplaatsen. Het gaat om het vinden van een professional die de nuances van gegevenskwaliteit, prestaties en veranderende bedrijfsbehoeften begrijpt. We zoeken kandidaten met een sterke technische basis, praktische ervaring met moderne tools en een proactieve benadering van het oplossen van problemen. Idealiter onderhoudt je nieuwe ETL-ontwikkelaar niet alleen je gegevensstromen, maar verbetert hij ze ook voortdurend, zodat de gegevens van je organisatie altijd betrouwbaar, schaalbaar en klaar voor actie zijn.

{kind=link}