NEW
Proxify is bringing transparency to tech team performance based on research conducted at Stanford. An industry first, built for engineering leaders.
Learn more











ETL-udviklere bygger de pipelines, der flytter og omdanner rådata til brugbare formater til business intelligence, analyse og maskinlæring. Denne guide gennemgår alt, hvad du skal vide for at ansætte de bedste ETL-talenter, som vil hjælpe din organisation med at udnytte data effektivt.
Om ETL-udvikling
ETL-udvikling er kernen i data engineering. Det indebærer at udtrække data fra forskellige kilder, omdanne dem til at opfylde forretningsbehov og indlæse dem i en lagringsløsning som et datalager eller en datasø.
Dagens ETL-udviklere arbejder med værktøjer som Apache Airflow, Talend, Informatica, Azure Data Factory og dbt (data build tool). De koder ofte i SQL, Python eller Java og bruger i stigende grad cloud-baserede tjenester fra AWS, Azure og Google Cloud.
En erfaren ETL-udvikler sikrer ikke kun, at data flyttes pålideligt, men også at de er rene, optimerede og klar til downstream-brug som f.eks. dashboards, rapportering og prædiktiv modellering.
ETL vs. ELT
Mens ETL (Extract, Transform, Load) og ELT (Extract, Load, Transform) tjener samme formål i dataintegration, er rækkefølgen af operationer og ideelle brugsscenarier meget forskellige. I traditionelle ETL-workflows transformeres data, før de indlæses i destinationssystemet - ideelt til lokale miljøer, og når transformationerne er komplekse eller følsomme.
ELT vender derimod op og ned på denne rækkefølge ved først at indlæse rådata i et målsystem - normalt et moderne cloud-datalager som Snowflake, BigQuery eller Redshift- og derefter transformere dem på stedet.
Denne tilgang udnytter cloud-platformenes skalerbare computerkraft til at håndtere store datasæt mere effektivt og forenkler pipeline-arkitekturen. Valget mellem ETL og ELT handler ofte om infrastruktur, datamængde og specifikke forretningskrav.
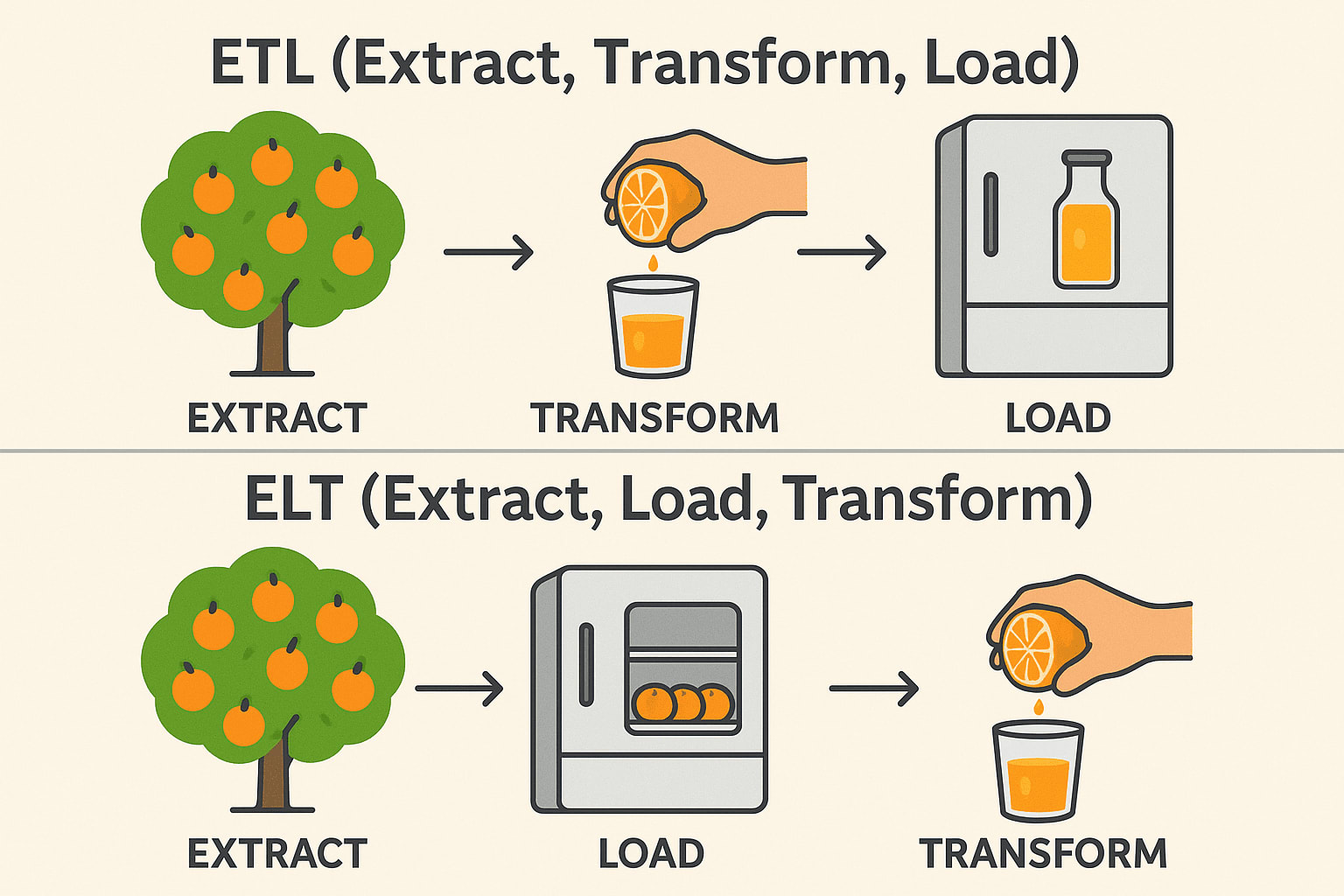
ETL (Udtræk → Transformér → Indlæs)
Extract: Pluk appelsiner fra træet (Indsaml rådata fra databaser, API'er eller filer). Transform: Pres dem til juice, før de gemmes (Rens, filtrer og formater dataene). Load: Opbevar den færdige juice i køleskabet (Gem strukturerede data i et datalager). Almindeligvis brugt i: Finans og sundhedspleje (data skal være rene før lagring).
ELT (Udtræk → Indlæs → Transformér)
Extract: Pluk appelsiner fra træet (Indsaml rådata fra databaser, API'er eller filer). Load: Opbevar de hele appelsiner i køleskabet først (Gem rådata i en datasø eller et cloud warehouse). Transform: Lav juice, når det er nødvendigt (bearbejd og analysér data senere). Almindeligvis brugt i: Big Data & Cloud (hurtigere, skalerbare transformationer). Teknisk stak: Snowflake, BigQuery, Databricks, AWS Redshift.
Brancher og applikationer
ETL-udviklere er uundværlige på tværs af flere brancher, herunder:
- Finance: Konsolidering af transaktionsdata til rapportering og afsløring af svindel.
- Sundhedspleje: Integrering af patientjournaler på tværs af forskellige systemer til analyse.
- Detail- og e-handel: Centralisering af kunde- og salgsdata til målrettet markedsføring og lagerstyring.
- Telekommunikation: Aggregering af brugsdata for at informere om serviceforbedringer.
- Teknologi: Opbygning af pålidelige data backbones til SaaS-platforme og AI-modeller.
Uanset branche er virksomheder i stigende grad afhængige af nøjagtige, rettidige data, hvilket gør dygtige ETL-udviklere til et kritisk aktiv.
Must-have færdigheder for ETL-udviklere
Når du ansætter en ETL-udvikler, skal du prioritere kandidater, der demonstrerer disse kernekompetencer:
- Stærk SQL-viden: SQL er fortsat databasernes lingua franca. ETL-udviklere skal skrive effektive forespørgsler for at udtrække og transformere data præcist og hurtigt.
- Erfaring med ETL-værktøjer: Praktisk erfaring med ETL-platforme som Informatica, Talend eller Airflow sikrer, at de kan opbygge robuste og skalerbare pipelines uden at genopfinde hjulet.
- Datamodellering: ETL-udviklere skal forstå, hvordan data er struktureret. At vide, hvordan man designer skemaer som stjerne- og snefnugmodeller, sikrer, at data organiseres effektivt til rapportering og analyse.
- Skriptsprog: Sprog som Python eller Bash er afgørende for at opbygge brugerdefinerede scripts, automatisering og integrationer ud over, hvad ETL-værktøjer tilbyder ud af boksen.
- Cloud Data Services: Skiftet til skyen accelererer på grund af skalerbarhed, omkostningsbesparelser og administrerede tjenester. Færdigheder i AWS Glue, Azure Data Factory eller Google Clouds Dataflow betyder, at udvikleren kan arbejde i moderne, fleksible miljøer, hvor infrastrukturen kan vokse med din virksomheds behov.
- Problemløsning: ETL-arbejde er fuld af overraskelser - uventede dataafvigelser, mislykkede indlæsninger og flaskehalse i ydeevnen. Stærke problemløsningsevner sikrer, at udviklere kan diagnosticere og løse problemer hurtigt uden at afspore driften.
- Performance tuning: Når datamængderne stiger, betyder effektivitet noget. Udviklere, der ved, hvordan man optimerer pipelines, hjælper med at reducere omkostninger, spare tid og forbedre pålideligheden af hele dataøkosystemet.
En ETL-udvikler i topklasse skriver også klar, vedligeholdelsesvenlig kode og forstår principperne for datastyring og -sikkerhed.
Nice-to-have færdigheder
Selv om det ikke er obligatorisk, kan følgende færdigheder adskille gode ETL-udviklere:
- Erfaring med streaming af data: Realtidsanalyse bliver mere og mere populært. At vide, hvordan man arbejder med værktøjer som Kafka eller Spark Streaming, gør det muligt for udviklere at bygge løsninger, der reagerer øjeblikkeligt på nye data.
- Kendskab til API'er: Da virksomheder integrerer med utallige tredjepartsplatforme, bliver API-kendskab en betydelig fordel for problemfri integration af forskellige datakilder.
- Containerization: Værktøjer som Docker og Kubernetes gør ETL-implementeringer mere bærbare og modstandsdygtige og hjælper organisationer med at administrere miljøer mere effektivt.
- En dyb forståelse af warehouses som Snowflake, Redshift eller BigQuery gør det muligt for udviklere at optimere indlæsning og forespørgsel af massive datasæt.
- DevOps og CI/CD: Automatiserede implementeringer og testpipelines er ved at blive standard inden for datateknik, hvilket sikrer hurtigere og mere pålidelige opdateringer af ETL-processer.
- Business Intelligence-integration: Udviklere, der tilpasser deres pipelines til rapporteringsværktøjer som Tableau, Power BI eller Looker, tilføjer endnu mere værdi ved at muliggøre problemfri adgang til rene, strukturerede data.
Disse ekstra funktioner kan give betydelig værdi, efterhånden som dine databehov bliver mere sofistikerede.
Interviewspørgsmål og eksempler på svar
Her er nogle tankevækkende spørgsmål, der kan hjælpe dig med at vurdere kandidaterne:
1. Kan du beskrive den mest komplekse ETL-pipeline, du har bygget?
Se efter: Størrelse på datasæt, antal transformationer, fejlhåndteringsstrategier.
Eksempel på svar: Jeg byggede en pipeline, der udtrak brugerhændelsesdata fra flere apps, rensede og sammenføjede dataene, berigede dem med tredjepartsoplysninger og indlæste dem i Redshift. Jeg optimerede belastningen ved at partitionere data og brugte AWS Glue til orkestrering.
2. Hvordan sikrer du datakvalitet gennem hele ETL-processen?
Se efter: Datavalideringsmetoder, afstemningstrin, fejllogning.
Eksempel på svar: Jeg implementerer kontrolpunkter på hvert trin, bruger dataprofileringsværktøjer, logger uregelmæssigheder automatisk og opsætter alarmer, når tærsklerne overskrides.
3. Hvordan ville du optimere et ETL-job, der kører for langsomt?
Se efter: Partitionering, parallel behandling, optimering af forespørgsler og hardwaretuning.
Eksempel på svar: Jeg starter med at analysere forespørgselsudførelsesplaner, refaktorerer derefter transformationer for effektivitet, introducerer inkrementelle belastninger og opskalerer om nødvendigt beregningsressourcer.
4. Hvordan håndterer du skemaændringer i kildedata?
Se efter: Strategier for tilpasningsevne og robusthed.
Eksempel på svar: Jeg bygger skemavalidering ind i pipelinen, bruger versionsstyring til skemaopdateringer og designer ETL-jobs til at tilpasse sig dynamisk eller fejle elegant med advarsler.
5. Hvad er din erfaring med cloud-baserede ETL-værktøjer?
Se efter: Praktisk erfaring snarere end blot teoretisk viden.
Eksempel på svar: Jeg har brugt AWS Glue og Azure Data Factory i stor udstrækning, designet serverløse pipelines og udnyttet native integrationer med storage- og compute-tjenester.
6. Hvordan ville du designe en ETL-proces til at håndtere både fulde belastninger og inkrementelle belastninger?
Eksempel på svar: Ved fuld indlæsning designer jeg ETL'en til at afkorte og genindlæse måltabellerne, hvilket er velegnet til små til mellemstore datasæt. Til inkrementelle indlæsninger implementerer jeg CDC-mekanismer (Change Data Capture), enten via tidsstempler, versionsnumre eller databasetriggere. For eksempel kan jeg i en PostgreSQL-opsætning udnytte logiske replikeringsslots til kun at trække de ændrede rækker siden den sidste synkronisering.
7. Hvilke skridt ville du tage for at fejlfinde en datapipeline, der fejler med jævne mellemrum?
Svareksempel: Først gennemgår jeg pipeline-logfilerne for at finde mønstre, f.eks. tidsbaserede fejl eller dataafvigelser. Derefter isolerer jeg den fejlbehæftede opgave - hvis det er et transformationstrin, kører jeg det igen med eksempeldata lokalt. Jeg sætter ofte retries op med eksponentiel backoff og alarmer via værktøjer som PagerDuty for at sikre en rettidig reaktion på fejl.
8. Kan du forklare forskellene mellem batchbehandling og realtidsbehandling, og hvornår du ville vælge den ene frem for den anden?
Eksempel på svar: Batchbehandling indebærer indsamling af data over tid og behandling af dem i bulk, hvilket er perfekt til rapporteringssystemer, der ikke har brug for indsigt i realtid, som f.eks. salgsrapporter ved dagens slutning. Realtidsbehandling ved hjælp af teknologier som Apache Kafka eller AWS Kinesis er afgørende for brugssager som afsløring af svindel eller anbefalingsmotorer, hvor millisekunder betyder noget.
9. Hvordan håndterer du afhængigheder mellem flere ETL-jobs?
Eksempel på svar: Jeg bruger orkestreringsværktøjer som Apache Airflow, hvor jeg definerer Directed Acyclic Graphs (DAGs) til at udtrykke jobafhængigheder. For eksempel kan en DAG specificere, at 'extract'-opgaven skal være færdig, før 'transform' begynder. Jeg bruger også Airflows sensormekanismer til at vente på eksterne udløsere eller tilgængelighed af upstream-data.
10. Hvordan vil du i et cloud-miljø sikre følsomme data under ETL-processen?
Svareksempel: Jeg krypterer data både i hvile og i transit ved hjælp af værktøjer som AWS KMS til krypteringsnøgler. Jeg håndhæver strenge IAM-politikker, der sikrer, at kun autoriserede ETL-jobs og -tjenester kan få adgang til følsomme data. I pipelines maskerer eller tokeniserer jeg følsomme felter som PII (personligt identificerbare oplysninger) og vedligeholder detaljerede revisionslogfiler for at overvåge adgang og brug.
Resumé
At ansætte en ETL-udvikler handler om mere end bare at finde en person, der kan flytte data fra punkt A til punkt B. Det handler om at finde en professionel, der forstår nuancerne i datakvalitet, ydeevne og skiftende forretningsbehov. Vi leder efter kandidater med et stærkt teknisk fundament, praktisk erfaring med moderne værktøjer og en proaktiv tilgang til problemløsning. Ideelt set vil din nye ETL-udvikler ikke kun vedligeholde dine datastrømme, men også løbende forbedre dem og sikre, at din organisations data altid er pålidelige, skalerbare og klar til handling.




